Build Lakehouses with Delta Lake
Delta Lake is an open-source storage framework that enables building a format agnostic Lakehouse architecture with compute engines including Spark, PrestoDB, Flink, Trino, Hive, Snowflake, Google BigQuery, Athena, Redshift, Databricks, Azure Fabric and APIs for Scala, Java, Rust, and Python. With Delta Universal Format aka UniForm, you can read now Delta tables with Iceberg and Hudi clients.


Open
Community driven, rapidly expanding integration ecosystem

Simple
One format to unify your ETL, Data warehouse, ML in your lakehouse

UniForm
A universal format for lakehouse interoperability

Production Ready
Battle tested in over 10,000+ production environments

Platform Agnostic
Use with any query engine on any cloud, on-prem, or locally





Key Features
ACID Transactions
Protect your data with serializability, the strongest level of isolation

Scalable Metadata
Handle petabyte-scale tables with billions of partitions and files with ease

Time Travel
Access/revert to earlier versions of data for audits, rollbacks, or reproduce

Open Source
Community driven, open standards, open protocol, open discussions

Unified Batch/Streaming
Exactly once semantics ingestion to backfill to interactive queries

Schema Evolution / Enforcement
Prevent bad data from causing data corruption

Audit History
Delta Lake log all change details providing a fill audit trail

DML Operations
SQL, Scala/Java and Python APIs to merge, update and delete datasets

Delta Lake: The Definitive Guide
Building modern data lakehouse architectures with Delta Lake with forewords by Michael Armbrust and Dominique Brezinski.
DownloadRead the Lakehouse Storage Systems Whitepapers
These whitepapers dive into the features of Lakehouse storage systems and compare Delta Lake, Apache Hudi, and Apache Iceberg. They also explain the benefits of Lakehouse storage systems and show key performance benchmarks.
Read the whitepaper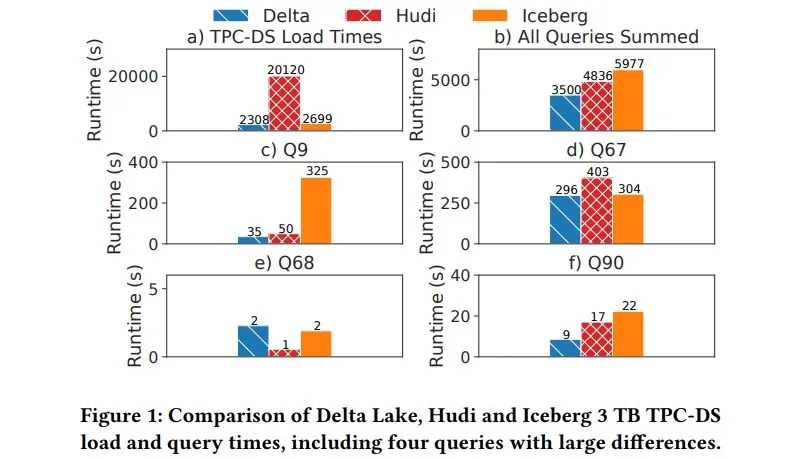
Organizations that have contributed to Delta Lake
Together we have made Delta Lake the most widely used lakehouse format in the world!

























Join the Delta Lake Community
Delta Lake is supported by more than 190 developers from over 70
organizations across multiple repositories.
Chat with fellow Delta Lake users and contributors, ask questions and share
tips.






Project Governance
Delta Lake is an independent open-source project and not controlled by any single company. To emphasize this we joined the Delta Lake Project in 2019, which is a sub-project of the Linux Foundation Projects. Within the project, we make decisions based on these rules.