Diving into Delta Lake Online Tech Talk Series
By Denny Lee
For our next series of Delta Lake online tech talks, we’re excited to dive into the internals with our Diving into Delta Lake series. This will be a fun set of tech talks with live demos and Q&A. Check them out!
Diving into Delta Lake: Unpacking the Transaction Log
March 26, 2020 | 09
am PT Watch now!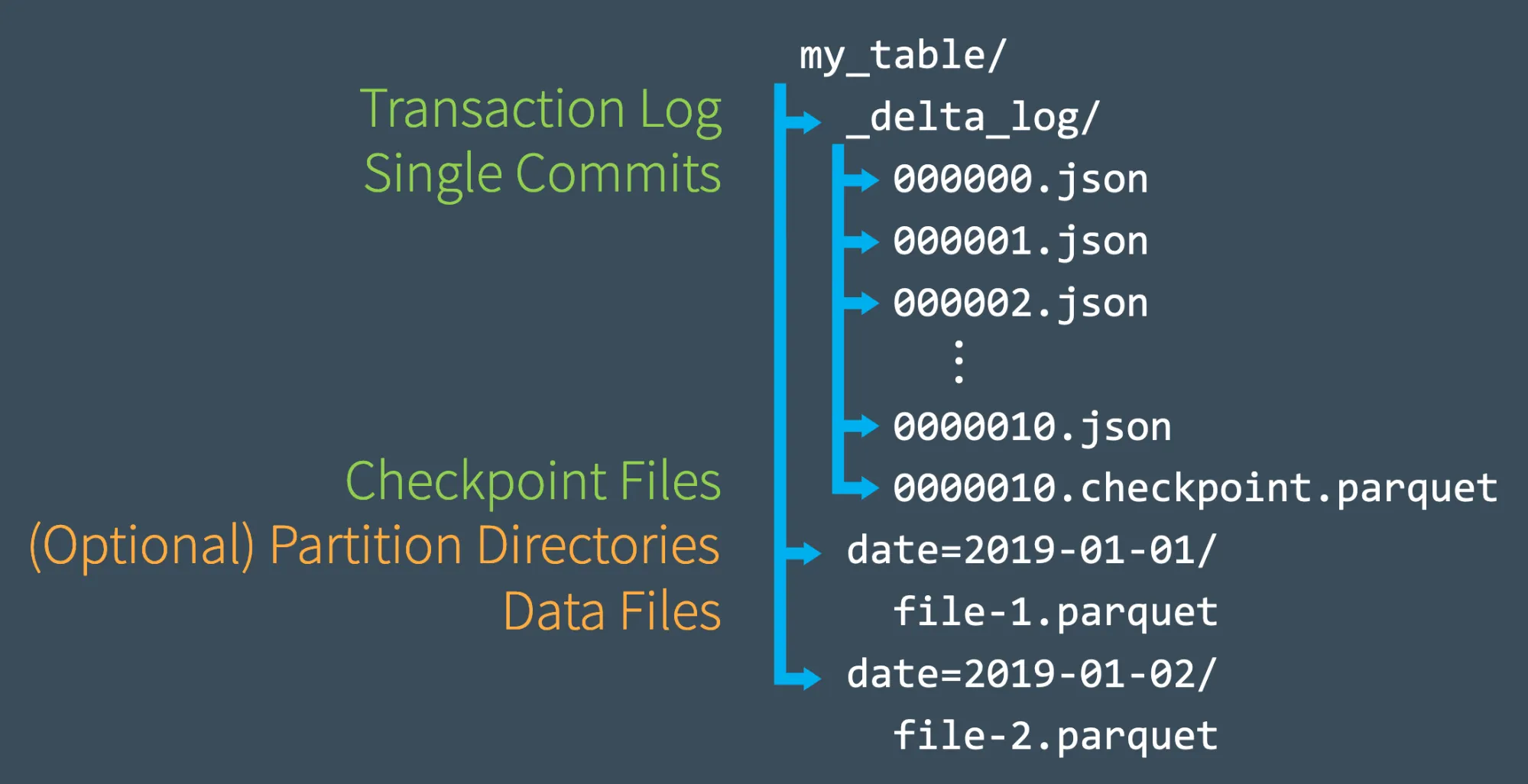
The transaction log is key to understanding Delta Lake because it is the common thread that runs through many of its most important features, including ACID transactions, scalable metadata handling, time travel, and more. In this session, we’ll explore what the Delta Lake transaction log is, how it works at the file level, and how it offers an elegant solution to the problem of multiple concurrent reads and writes. In this webinar you will learn about:
- What is the Delta Lake Transaction Log
- What is the transaction log used for?
- How does the transaction log work?
- Reviewing the Delta Lake transaction log at the file level
- Dealing with multiple concurrent reads and writes
- How the Delta Lake transaction log solves other use cases including Time Travel and Data Lineage and Debugging
Speakers
Burak Yavuz Senior Software Engineer, Databricks Burak Yavuz is a Software Engineer at Databricks. He has been contributing to Spark since Spark 1.1, and is the maintainer of Spark Packages. Burak received his BS in Mechanical Engineering at Bogazici University, Istanbul, and his MS in Management Science & Engineering at Stanford.
Denny Lee Developer Advocate, Databricks Denny Lee is a Developer Advocate at Databricks. He is a hands-on distributed systems and data sciences engineer with extensive experience developing internet-scale infrastructure, data platforms, and predictive analytics systems for both on-premise and cloud environments. He also has a Masters of Biomedical Informatics from Oregon Health and Sciences University and has architected and implemented powerful data solutions for enterprise Healthcare customers. His current technical focuses include Distributed Systems, Apache Spark, Deep Learning, Machine Learning, and Genomics.
Diving into Delta Lake: Schema Enforcement and Evolution
April 2, 2020 | 09
am PT Watch Now!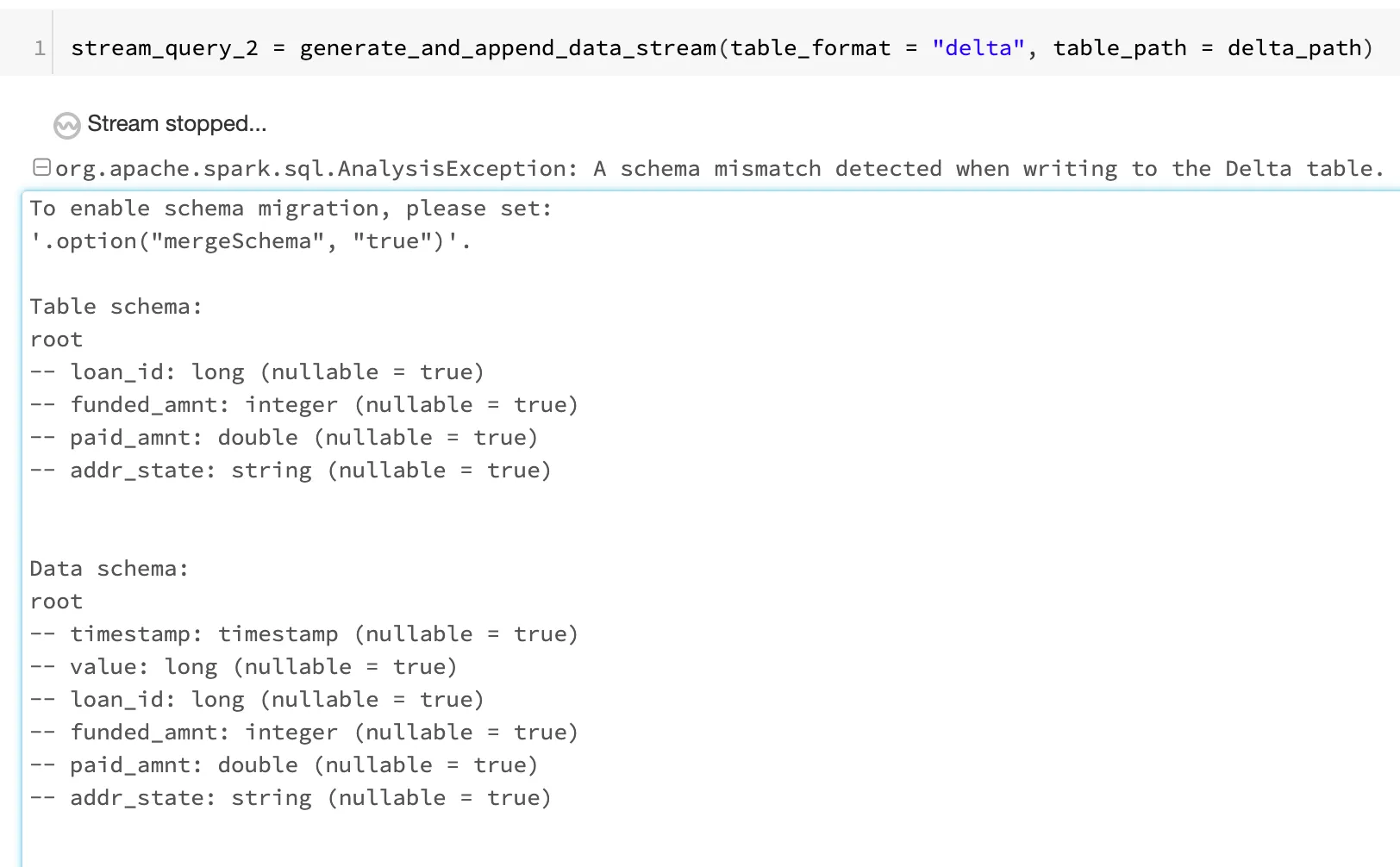
Data, like our experiences, is always evolving and accumulating. To keep up, our mental models of the world must adapt to new data, some of which contains new dimensions — new ways of seeing things we had no conception of before. These mental models are not unlike a table’s schema, defining how we categorize and process new information.
This brings us to schema management. As business problems and requirements evolve over time, so too does the structure of your data. With Delta Lake, as the data changes, incorporating new dimensions is easy. Users have access to simple semantics to control the schema of their tables. These tools include schema enforcement, which prevents users from accidentally polluting their tables with mistakes or garbage data, as well as schema evolution, which enables them to automatically add new columns of rich data when those columns belong. In this webinar, we’ll dive into the use of these tools. In this webinar you will learn about:
- Understanding table schemas and schema enforcement
- How does schema enforcement work?
- How is schema enforcement useful?
- Preventing data dilution
- How does schema evolution work?
- How is schema evolution useful?
Speakers
Andreas Neumann Staff Software Engineer, Databricks Andreas Neumann is a software engineer at Databricks, where he focuses on Structured Streaming and Delta Lake. He has previously built big data systems at Google, Cask Data, Yahoo! and IBM. Andreas holds a PhD in computer science from the University of Trier, Germany.
Denny Lee Developer Advocate, Databricks Denny Lee is a Developer Advocate at Databricks. He is a hands-on distributed systems and data sciences engineer with extensive experience developing internet-scale infrastructure, data platforms, and predictive analytics systems for both on-premise and cloud environments. He also has a Masters of Biomedical Informatics from Oregon Health and Sciences University and has architected and implemented powerful data solutions for enterprise Healthcare customers. His current technical focuses include Distributed Systems, Apache Spark, Deep Learning, Machine Learning, and Genomics.
Diving into Delta Lake: DML Internals
April 16, 2020 | 9
am PT Watch now!
In the earlier Delta Lake Internals webinar series sessions, we described how the Delta Lake transaction log works. In this session, we will dive deeper into how commits, snapshot isolation, and partition and files change when performing deletes, updates, merges, and structured streaming. In this webinar you will learn about:
- A quick primer on the Delta Lake Transaction Log
- Understand the fundamentals when running DELETE, UPDATE, and MERGE
- Understand the actions performed when performing these tasks
- Understand the basics of partition pruning in Delta Lake
- How do streaming queries work within Delta Lake
Speakers
Tathagata Das Staff Software Engineer, Databricks Tathagata Das is an Apache Spark committer and a member of the PMC. He’s the lead developer behind Spark Streaming and currently develops Structured Streaming. Previously, he was a grad student at the UC Berkeley at AMPLab, where he conducted research about data-center frameworks and networks with Scott Shenker and Ion Stoica.
Denny Lee Developer Advocate, Databricks Denny Lee is a Developer Advocate at Databricks. He is a hands-on distributed systems and data sciences engineer with extensive experience developing internet-scale infrastructure, data platforms, and predictive analytics systems for both on-premise and cloud environments. He also has a Masters of Biomedical Informatics from Oregon Health and Sciences University and has architected and implemented powerful data solutions for enterprise Healthcare customers. His current technical focuses include Distributed Systems, Apache Spark, Deep Learning, Machine Learning, and Genomics.