Delta Lake on GCP
By Avril Aysha
This article shows you how to use Delta Lake with Google Cloud Platform (GCP).
Delta Lake is an open-source framework for fast, reliable data storage. It supports ACID transactions, handles metadata efficiently at scale, optimizes query performance and allows time travel. You can use Delta Lake to build a high-performing lakehouse architecture.
GCP is a popular cloud service. Many organizations use its object store Google Cloud Storage to build a data lake, for example with Parquet files. Storage on GCP is cheap and accessing it is efficient, especially for batch workloads. Data lakes on GCS do not natively support transactional guarantees or many of the query optimizations that Delta Lake provides.
This article will show you how to read and write Delta tables from and to GCP. We’ll work through code examples with Spark and Polars.
You will learn:
- Why Delta Lake is a great choice for GCP workloads
- How to configure your Spark session for proper GCP access with Delta Lake
- How to set up your Python environment for proper GCP access with Delta Lake
Let’s get started.
Why Delta Lake is great for GCP
Cloud object storage systems are slow at listing files. This can be a big issue when you’re dealing with large amounts of data. Delta Lake improves the efficiency of your queries on data in these object stores.
Unlike traditional file systems, cloud storage uses a flat namespace. This means there are no true directories. Instead, directories are simulated with prefixes on object keys. So, when listing files, the system has to scan everything and filter by these prefixes.
Cloud storage also has API rate limits, so each file listing often requires multiple API calls. When you need to list a large number of files, this can create a serious bottleneck.
Delta Lake avoids these issues by storing all file paths in a transaction log. Instead of listing files, your engine can quickly access the paths of relevant files in a single operation. This makes querying much faster and more efficient.
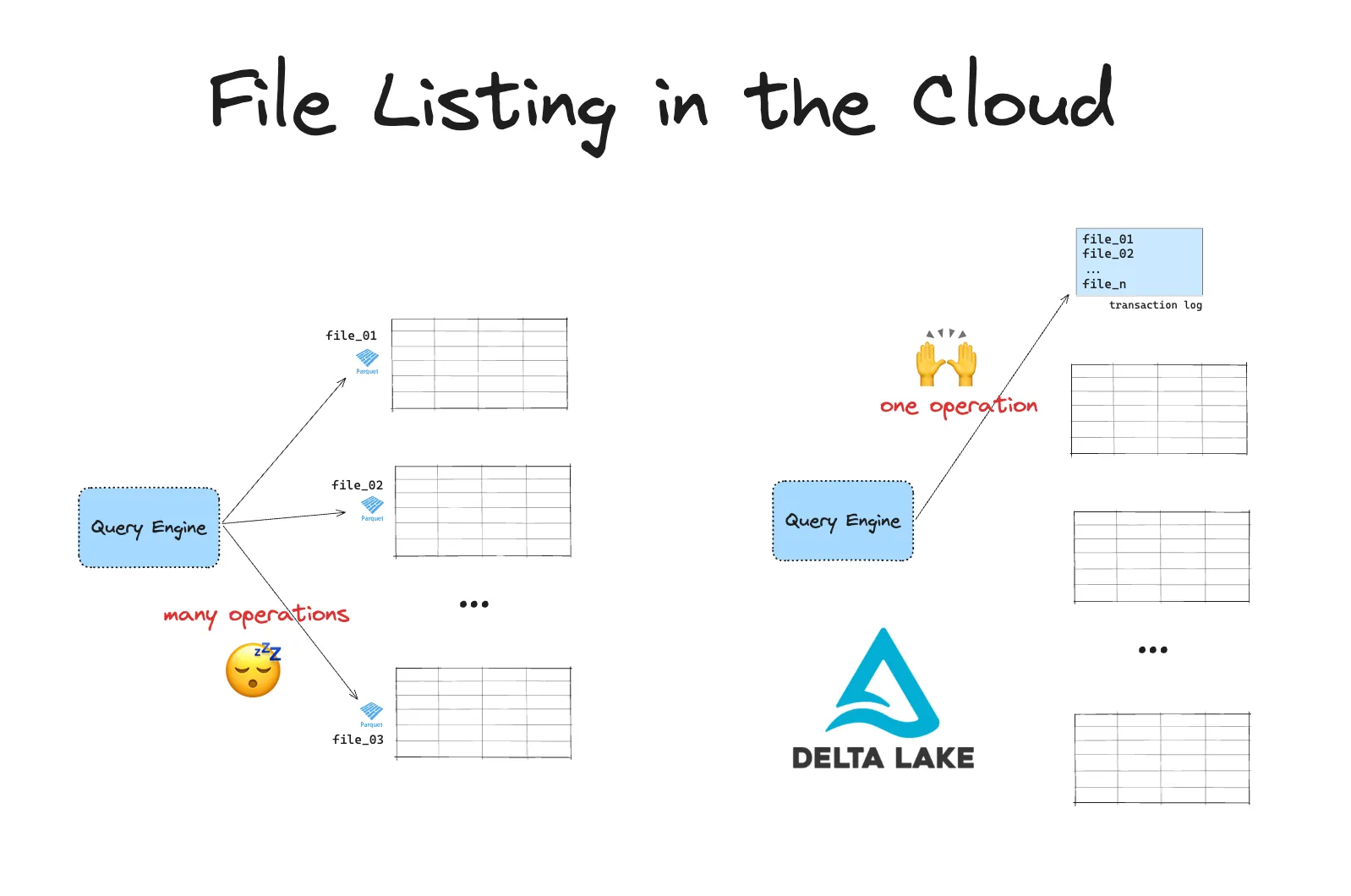
Building a lakehouse architecture with Delta Lake has many more benefits compared to data lakes on GCP. You can read about them in the Delta Lake vs Data Lake blog.
How to use Delta Lake on GCP
Many query engines support reading and writing Delta Lake on GCP.
For example, you can read Delta Lake tables with Spark using:
df = spark.read.format("delta").load(path/to/delta)And you can write data to Delta Lake table with Spark using:
df.write.format("delta").save(path/to/delta)You can also use Delta Lake without Spark.
Some query engines require a few extra configuration steps to get up and running with Delta Lake. The following two sections will walk you through working with Delta Lake on GCP with Spark and with Python engines like Polars.
First, let’s set up our Google Cloud Storage bucket correctly.
Setting Up Google Cloud Storage (GCS)
No matter which query engine you will use, you will need the following:
- a Google Cloud account: You’ll need access to a Google Cloud project.
- the Google Cloud SDK: Install the Google Cloud SDK.
Once you have these set up, create a Google Cloud Storage bucket. This will serve as the storage location for your Delta Lake data.
- Go to the Google Cloud Console.
- Open Storage and select Buckets.
- Click Create bucket and follow the instructions. Give your bucket a unique name, select a location, and choose your storage class.
- After creating the bucket, note the bucket name and location.
Make sure to configure appropriate permissions for the bucket. You’ll need to grant permissions for the service account used by your query engine to read and write to this bucket.
Let’s now look at an example of using Delta Lake on GCP with the Spark engine.
How to use Delta Lake on GCP with Spark
We will demonstrate code using a local Spark session for this article. You can also use fully managed services like Google Dataproc or Databricks.
Here is a common error that users will see when they have not configured their Spark session correctly:
java.lang.RuntimeException: java.lang.ClassNotFoundException: Class com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem not foundThis indicates that Spark has not been set up with the correct GoogleHadoopFileSystem. If you encounter this error, you likely are missing the gcs-connector JAR and/or have not set the spark.hadoop.fs.gs.impl config correctly.
The code below is a working example for starting a Spark session that is correctly configured:
conf = (
pyspark.conf.SparkConf()
.setAppName("MyApp")
.set(
"spark.sql.catalog.spark_catalog",
"org.apache.spark.sql.delta.catalog.DeltaCatalog",
)
.set("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.set("spark.hadoop.fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")
.set("spark.hadoop.google.cloud.auth.service.account.enable", "true")
.set("spark.hadoop.google.cloud.auth.service.account.json.keyfile", "/Users/rpelgrim/Desktop/gcs.json")
.set("spark.sql.shuffle.partitions", "4")
.set("spark.jars", "https://storage.googleapis.com/hadoop-lib/gcs/gcs-connector-hadoop3-latest.jar") \
.setMaster(
"local[*]"
) # replace the * with your desired number of cores. * to use all.
)
builder = pyspark.sql.SparkSession.builder.appName("MyApp").config(conf=conf)
spark = configure_spark_with_delta_pip(builder).getOrCreate()Let’s work through the configuration step by step.
1. Configure Authentication
To access your GCS bucket with Spark, you will need to authenticate using a Google Cloud service account. To do so, you will need to generate a service account key. Here’s how to do it:
- Create a service account:
In the Google Cloud Console:- Go to IAM & Admin > Service Accounts.
- Click Create Service Account.
- Assign the
Storage Adminrole to the service account for access to the GCS bucket.
- Generate a key for your service account:
- Under the service account, click Manage Keys > Add Key > Create new key.
- Select JSON as the key type, and download the key. Note the path where you store it.
In a moment, we’ll use the path to the service account key when we configure our Spark session.
2. Install GCS Connector JAR
You will need to set two more configurations to set up working with Delta Lake on GCP:
- Download and install the
gcs-connectorJAR file and add it to your Spark session - Configure GCS as a file system.
We will do this all in by setting the following configurations in our Spark session:
.set("spark.jars", "https://storage.googleapis.com/hadoop-lib/gcs/gcs-connector-hadoop3-latest.jar")
.set("spark.hadoop.fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")
.set("spark.hadoop.google.cloud.auth.service.account.enable", "true")
.set("spark.hadoop.google.cloud.auth.service.account.json.keyfile", "/path/to/key.json")Replace /path/to/key.json with the path to your Service Account key JSON file.
Running this code will spin up a Spark session that is properly configured to work with Delta Lake on GCP.
.set("spark.jars", …)adds the correct gcs-connector JAR..set("spark.hadoop.fs.gs.impl", …)sets the correct file system- the
.set("spark.hadoop.google.cloud.auth…configs set the authentication
3. Write Data to Delta Lake on GCP
Now you’re ready to start writing data to Delta Lake on GCP.
Let’s create a sample DataFrame and write it as a Delta table to your GCS bucket:
data = spark.range(0, 5)
data.write.format("delta").save("gs://your-bucket-name/delta-table")Replace your-bucket-name with your actual GCS bucket name.
4. Read Data from Delta Lake on GCS
Let’s read the data back in to confirm that this has worked as expected:
df = spark.read.format("delta").load("gs://your-bucket-name/delta-table")
df.show()
+---+
| id|
+---+
| 3|
| 4|
| 1|
| 2|
| 0|
+---+This successfully reads the Delta table directly from your GCS bucket.
5. Perform Updates and Deletes with Delta Lake
Delta Lake provides powerful capabilities for handling updates, deletes, and merges. Let’s go over a few examples.
Update: Update values in your Delta table based on a condition.
from delta.tables import DeltaTable
deltaTable = DeltaTable.forPath(spark, "gs://your-bucket-name/delta-table")
# Update rows where id is less than 3
deltaTable.update("id < 3", {"id": "id + 10"})Delete: Remove rows that match a specific condition.
# Delete rows where id is less than 5
deltaTable.delete("id < 5")Merge: Merge new data into your Delta table, based on specific conditions.
new_data = spark.range(0, 20)
deltaTable.alias("old").merge(
new_data.alias("new"),
"old.id = new.id"
).whenMatchedUpdate(set={"id": "new.id"}).whenNotMatchedInsert(values={"id": "new.id"}).execute()See the Delta Lake Merge post for more details.
6. Use Delta Lake Time Travel
Time travel is a great Delta Lake feature which lets you access older versions of your data. Here’s how you can do it.
You can use the versionAsOf option to read a specific version. The first version is version 0.
# read a specific version of a Delta table
> df_version = spark.read.format("delta").option("versionAsOf", 1).load("gs://your-bucket-name/delta-table")
+---+
| id|
+---+
| 4|
| 11|
| 3|
| 12|
| 10|
+---+You can also reference versions using the timestamp on which they were saved:
# read based on a timestamp
df_timestamp = spark.read.format("delta").option("timestampAsOf", "2023-01-01").load("gs://your-bucket-name/delta-table")Replace "2023-01-01" with your target date.
See the Delta Lake Time Travel post for more information.
How to use Delta Lake on GCP with Polars
You can also use Delta Lake on GCP with Polars and other Python query engines.
import polars as pl
df = pl.DataFrame(
{
"foo": [1, 2, 3, 4, 5],
"bar": [6, 7, 8, 9, 10],
"ham": ["a", "b", "c", "d", "e"],
}
)
table_path = "gs://avriiil/test-delta-polars"
df.write_delta(
table_path,
)Let’s confirm this has worked by reading it back in:
> df_read = pl.read_delta(table_path)
| | foo | bar | ham |
|---:|------:|------:|:------|
| 0 | 1 | 6 | a |
| 1 | 2 | 7 | b |
| 2 | 3 | 8 | c |
| 3 | 4 | 9 | d |
| 4 | 5 | 10 | e |You don’t need to install any extra dependencies to read/write Delta tables to GCS with engines that use delta-rs, like Polars. You do need to configure your GCS access credentials correctly.
Application Default Credentials (ADC) is a strategy used by GCS to automatically find credentials based on the application environment. If you are working from your local machine and have ADC set up then you can read/write Delta tables from GCS directly, without having to pass your credentials explicitly.
Alternatively, you can pass GCS credentials to your query engine explicitly.
For Polars, you would do this using the storage_options keyword. This will forward your credentials to the object store library that Polars uses under the hood. Read the Polars documentation and the object store documentation for more information.
See the Delta Lake without Spark post for more examples of using Delta Lake from non-Spark engines.
Locking Provider for Delta Lake with GCS
Google Cloud Storage (GCS) natively supports atomic operations at the object level, which prevents conflicts and corruption during file creation. This means you do not need an additional locking provider to manage concurrent writes, unlike with AWS S3.
Here’s how it works:
- GCS enforces atomicity on object writes, meaning that each file creation or modification is treated as a single transaction. This prevents situations where multiple writers might simultaneously create or update the same file and cause data corruption.
- When a write request is made, GCS either completes the write fully or fails, but it will not leave a file in an incomplete or partially written state.
This means that in GCS, Delta Lake’s ACID properties, including isolation, are fully supported without needing a separate locking provider. You can rely on Delta Lake’s transaction log and the GCS atomic write mechanism to guarantee data consistency.
Using Delta Lake with GCP
In this article, you’ve set up Delta Lake on Google Cloud Storage and explored how to write, read, and manage data with Delta tables. By integrating Delta Lake with GCP, you gain a powerful tool for building scalable, reliable data lakes with the flexibility of Delta Lake’s features.
You can read and write Delta Lake tables on GCP. Using Delta Lake with GCS speeds up your queries by avoiding costly file listing operations.
Delta Lake works with many query engines on GCP. Spark sessions will need a bit of extra setup to get started.
No matter which engine you use, Delta Lake gives you these core benefits: faster queries, efficient metadata handling, and reliable transactions.