Delta Lake Optimize
By Avril Aysha
This blog shows you how to optimize your Delta Lake table to reduce the number of small files.
Small files can be a problem because they slow down your query reads. Listing, opening and closing many small files incurs expensive overhead. This is called “the Small File Problem”. You can reduce the Small File Problem overhead by combining the data into bigger, more efficient files.
There are 3 ways you can optimize your Delta Lake table:
- Offline Optimize
- Optimized Write
- Auto Compaction
Optimized WriteandAuto Compactionare new Delta Lake features, available since Delta 3.1.0.
Choosing the right optimization method for your use case can save you lots of compute at query runtime.
Small files cause slow reads
Suppose you have a Delta Lake table with many small files. Running a query on this dataset is possible, but not efficient.
The code below runs a query on a Delta table with 2 million rows. The Delta table is partitioned on the education column and has 1440 files per partition:
%%time
df = spark.read.format("delta").load("test/delta_table_1440")
res = df.where(df.education == "10th").collect()
CPU times: user 175 ms, sys: 20.1 ms, total: 195 ms
Wall time: 16.1 sNow compare this to the same query on the same 2M-rows of data stored in a Delta table with only 1 optimized file per partition:
%%time
df = spark.read.format("delta").load("test/delta_table_1")
res = df.where(df.education == "10th").collect()
CPU times: user 156 ms, sys: 16 ms, total: 172 ms
Wall time: 4.62 sThis query runs much faster.
Storing data in an optimized number of files will improve your out-of-the-box read performance. The optimized number of files is not always 1 file; depending on the size of your dataset, it might be more than 1. Read more in the maxFileSize section below.
What causes the Small File Problem?
Small data files can be caused by:
- User error: Users can repartition datasets and write out data with many small files.
- Working with immutable files: Immutable file formats like Parquet cannot be overwritten. This means that updates to these datasets will create new files, possibly leading to a small file problem.
- Partitioning: Partitioning a table on a high-cardinality column can lead to disk partitions with many small files.
- Frequent incremental updates: Tables with frequent, small updates are likely to have many small files. A table that is updated every 2 minutes will generate 5040 files per week.
It’s best to design systems to avoid creating many small files.
But sometimes this is unavoidable, for example when you’re working with a table in an immutable file format like Parquet that needs to be updated frequently.
Let’s take a look at how you can use offline optimization to optimize your Delta Lake table in this case.
Delta Lake Optimize: Manual Optimize
Suppose you have an ETL pipeline that ingests some data every day. The data is streamed into a partitioned Delta table that gets updated every minute.
This means you will end up with 1440 files per partition at the end of every day.
> # get n files per partition
> !ls test/delta_table/education\=10th/*.parquet | wc -l
1440Running a query on a Delta table with many small files is not efficient, as we saw above.
You can manually run the Delta OPTIMIZE command to optimize the number of files. This is done by compacting all the inefficient small files into larger files that are more efficient to read. The default file size written in each partition after this operation is 1 GB.
You can perform a compaction manually using:
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, "test/delta_table")
deltaTable.optimize().executeCompaction()Downstream queries on this optimized Delta table will now be faster.
Read more in the dedicated Small File Compaction post.
Delta Lake Optimize: Optimized Write
You don’t have to manually run the OPTIMIZE command. You can also configure optimizations to run automatically on your Delta Table. These automatic optimizations are: Optimized Write and Auto Compaction.
Optimized Write combines all the small writes to the same partition into a single write command before executing. This is great when multiple processes are writing to the same partitioned Delta table, i.e. a distributed write operation.
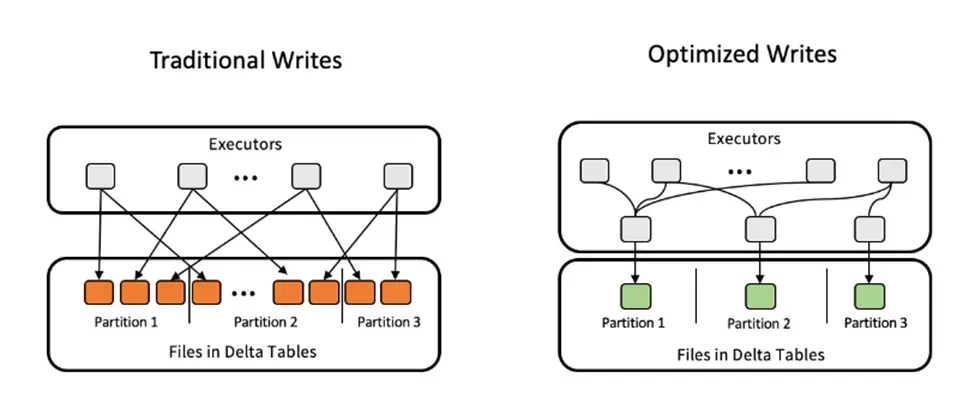
Optimized Write rebalances the data using a data shuffle before writing the files to the table. This way you will reduce the number of small files.
You can enable Optimized Write by setting the optimizeWrite option in your Delta Lake writer:
df.write.format("delta").option("optimizeWrite", "True").save("path/to/delta")You can also enable the Optimized Write functionality:
- for your whole Delta table by setting the
delta.autoOptimize.optimizeWritetable property. - for your whole Spark SQL session by setting the
spark.databricks.delta.optimizeWrite.enabledSQL configuration
Optimized Writes take a bit longer to execute because of the data shuffle that is performed before the data gets written. That’s why the feature is not enabled by default.
Optimized Write Example
Let’s look at an example. You can run this code for yourself in this notebook.
Spin up a local Spark cluster with 4 workers to simulate a distributed write setting:
import pyspark
from delta import *
builder = pyspark.sql.SparkSession.builder.master("local[4]").appName("parallel") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
spark = configure_spark_with_delta_pip(builder).getOrCreate()Then let’s start with a dataset with 2 millions rows of data:
df = spark.read.csv("data/census_2M.csv", header=True)Repartition this to simulate a situation with many small files:
df = df.repartition(1440)Write the data to a Delta table. Each of the 4 local processes will be writing many partitions in parallel:
df.write.format("delta").partitionBy("education").save("delta/census_table_many/")Let’s see how many files we have on disk per partition:
> # get n files per partition
> !ls delta/census_table_many/education\=10th/*.parquet | wc -l
1440There are 1440 files per partition on disk.
Let’s run a query on this Delta table with many small files:
> df_small = spark.read.format("delta").load("delta/census_table_many")
> %%time
> df_10th = df_small.where(df_small.education == "10th").collect()
CPU times: user 175 ms, sys: 20.1 ms, total: 195 ms
Wall time: 16.1 sNow let’s write the same data out using an Optimized Write. This will execute a data shuffle before the write operation and should avoid the Small File Problem:
df.write.format("delta").partitionBy("education").option("optimizeWrite", "True").save("delta/census_table_optimized/")Let’s see how many files we have on disk per partition:
> # get n files per partition
> !ls delta/census_table_optimized/education\=10th/*.parquet | wc -l
1All the data has been combined into 1 file per partition. This toy dataset is small (~250MB) so one file per partition makes sense here.
Now let’s run a query on this optimized Delta table:
> df_opt = spark.read.format("delta").load("delta/census_table_optimized")
> %%time
> df_10th = df_opt.where(df_opt.education == "10th").collect()
CPU times: user 146 ms, sys: 30.3 ms, total: 177 ms
Wall time: 3.66 sThis is a 4.5x performance gain.
Delta Lake Optimize: Auto Compaction
Optimized Write is great for distributed write situations with many different processes writing to the same Delta table.
But sometimes that is not enough to solve the Small File Problem, for example when you are writing frequent small updates to a table. In this case, the files will still be small, even after an Optimized Write.
Auto Compaction solves this problem by automatically running a small optimize command after every write operation. Data from files under a certain threshold size is automatically combined into a larger file. This way, your downstream queries can benefit from a more optimal file size.
You can enable Auto Compaction for your Delta table or your entire Spark session:
- Table property:
delta.autoOptimize.autoCompact - SparkSession setting:
spark.databricks.delta.autoCompact.enabled
Auto Compaction is only triggered for partitions or tables that have at least a certain number of small files. The minimum number of files required to trigger auto compaction can be configured with spark.databricks.delta.autoCompact.minNumFiles.
Let’s look at a quick example.
We’ll start with the same 2-million row dataset we used above and repartition it to simulate a situation with a write performed every minute:
df = spark.read.csv("data/census_2M.csv", header=True)
df = df.repartition(1440)Then let’s enable the Auto compaction feature for our Spark session:
spark.sql("SET spark.databricks.delta.autoCompact.enabled=true")Now let’s write the data to our Delta table:
df.write.format("delta").partitionBy("education").save("delta/census_table_compact/")Then perform a query:
df_comp = spark.read.format("delta").load("delta/census_table_compact")
%%time
df_10th = df_comp.where(df_comp.education == "10th").collect()
CPU times: user 205 ms, sys: 39.2 ms, total: 244 ms
Wall time: 4.69 sAgain we see a nice performance gain after optimizing the Delta table.
Delta Lake Optimize: Vacuum
Because Auto Compaction optimizes your Delta Table after the write operations, you may still have many small files on disk.
> # get n files per partition
> !ls delta/census_table_compact/education\=10th/*.parquet | wc -l
1441In this case we have 1440 files (one per partition) and 1 final file that contains all the data.
Delta Lake has iteratively combined all the small writes into a larger file. It has also recorded in the transaction log the path to the latest file. Downstream data reads will look at the transaction log and access only the last, largest file.
But as you can see the older, smaller files are still on disk. This doesn’t affect your read performance because Delta Lake knows that you only need to access the latest file. But you might still want to remove these files, for example to save on storage costs.
You can remove these older files with a VACUUM command. The parameter is the number of preceding hours you want to preserve.
deltaTable.vacuum(0)The VACUUM command removes old files that are no longer actively referenced in the transaction log. By default, VACUUM only affects files older than the default retention duration which is 7 days.
You can override this default setting using:
spark.sql("SET spark.databricks.delta.retentionDurationCheck.enabled=false")Read more in the dedicated VACUUM post.
Optimized Write vs Auto Compaction
Optimized Write combines many small writes to the same partition into one larger write operation. It is an optimization performed before the data is written to your Delta table.
Auto Compaction combines many small files into larger, more efficient files. It is an optimization performed after the data is written to your Delta table. You may need to perform a VACUUM operation afterwards to clean up the remaining small files.
Delta Lake Optimize maxFileSize
You can set the maximum file size of your files with the maxFileSize config option:
spark.databricks.delta.optimize.maxFileSize
The default setting of 1GB files works best in most scenarios. You don’t usually need to play with this.
The 1 GB default file size was selected from years of customer usage showing that this file size works well on common computational instances.
Delta Lake Optimize: Tradeoffs
All forms of optimization require computation and take time. Depending on your use case, one approach may be better suited than another.
Running optimizations usually makes sense if you have many downstream queries that will benefit from the faster read performance.
Delta Lake optimizations may not make sense for you if you need the lowest write latency possible.
Optimize your Delta Lake tables
Small files can cause slow downstream queries. Optimizing your Delta Lake table to avoid the Small File Problem is a great way to improve your out-of-the-box performance.
You can optimize your Delta Lake tables:
- Manually with the
optimize().executeCompaction()command - Before writing with the Optimized Write functionality
- After writing with the Auto Compaction functionality
Check out the notebook on Github to run the sample code for yourself.