Delta Lake vs. Parquet Comparison
This post explains the differences between Delta Lake and Parquet tables and why Delta Lakes are almost always a better option for real-world use cases. Delta Lake has all the benefits of Parquet tables and many other critical features for data practitioners. That’s why using a Delta Lake instead of a Parquet table is almost always advantageous.
Parquet tables are OK when data is in a single file but are hard to manage and unnecessarily slow when data is in many files. Delta Lake makes it easy to manage data in many Parquet files.
Let’s compare the basic structure of a Parquet table and a Delta table to understand Delta Lake’s advantages better.
Essential characteristics of Parquet files
Parquet is an immutable, binary, columnar file format with several advantages compared to a row-based format like CSV. Here are the core advantages of Parquet files compared to CSV:
- The columnar nature of Parquet files allows query engines to cherry-pick individual columns. For row-based file formats, query engines must read all the columns, even those irrelevant to the query.
- Parquet files contain schema information in the metadata, so the query engine doesn’t need to infer the schema / the user doesn’t need to manually specify the schema when reading the data.
- Columnar file formats like Parquet files are more compressible than row-based file formats.
- Parquet files store data in row groups. Each row group has min/max statistics for each column. Parquet allows query engines to skip over entire row groups for specific queries, which can be a huge performance gain when reading data.
- Parquet files are immutable, discouraging the antipattern of manually updating source data.
See this video on five reasons Parquet is better than CSV to learn more.
You can save small datasets in a single Parquet file without usability issues. A single Parquet file for a small dataset generally provides users with a much better data analysis experience than a CSV file.
However, data practitioners often have large datasets split across multiple Parquet files. Managing multiple Parquet files isn’t great.
The challenge of storing data in multiple Parquet files
A Parquet table consists of files in a data store. Here’s what a bunch of Parquet files look like on disk.
some_folder/
file1.parquet
file2.parquet
…
fileN.parquetMany of the usability benefits of a single Parquet file extend to Parquet data lakes - it’s easy to do column pruning on one Parquet file or many Parquet files.
Here are some of the challenges of working with Parquet tables:
- No ACID transactions for Parquet data lakes
- It is not easy to delete rows from Parquet tables
- No DML transactions
- There is no change data feed
- Slow file listing overhead
- Expensive footer reads to gather statistics for file skipping
- There is no way to rename, reorder, or drop columns without rewriting the whole table
- And many more
Delta Lake makes managing Parquet tables easier and faster. Delta Lake is also optimized to prevent you from corrupting your data table. Let’s look at how Delta Lakes are structured to understand how it provides these features.
The basic structure of a Delta Lake
Delta Lake stores metadata in a transaction log and table data in Parquet files. Here are the contents of a Delta table.
some_folder/
_delta_log
00.json
01.json
…
n.json
file1.parquet
file2.parquet
…
fileN.parquetHere’s a visual representation of a Delta table:
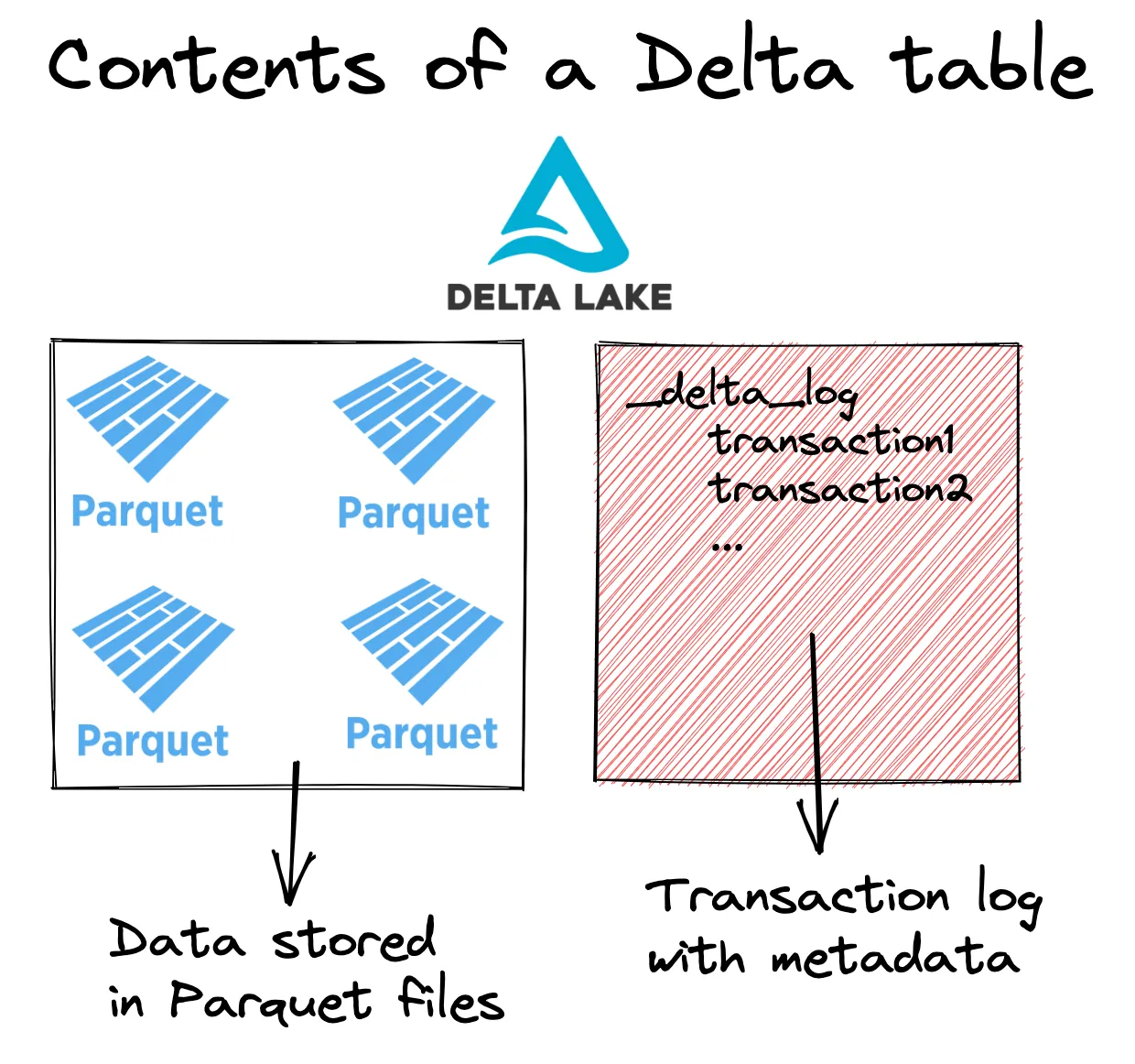
You can see the full Delta Lake specification by looking at the protocol. Let’s look at how Delta Lakes make file listing operations faster.
Delta Lake vs. Parquet: file listing
When you want to read a Parquet lake, you must perform a file listing operation and then read all the data. You can’t read the data till you’ve listed all the files. See the following illustration:
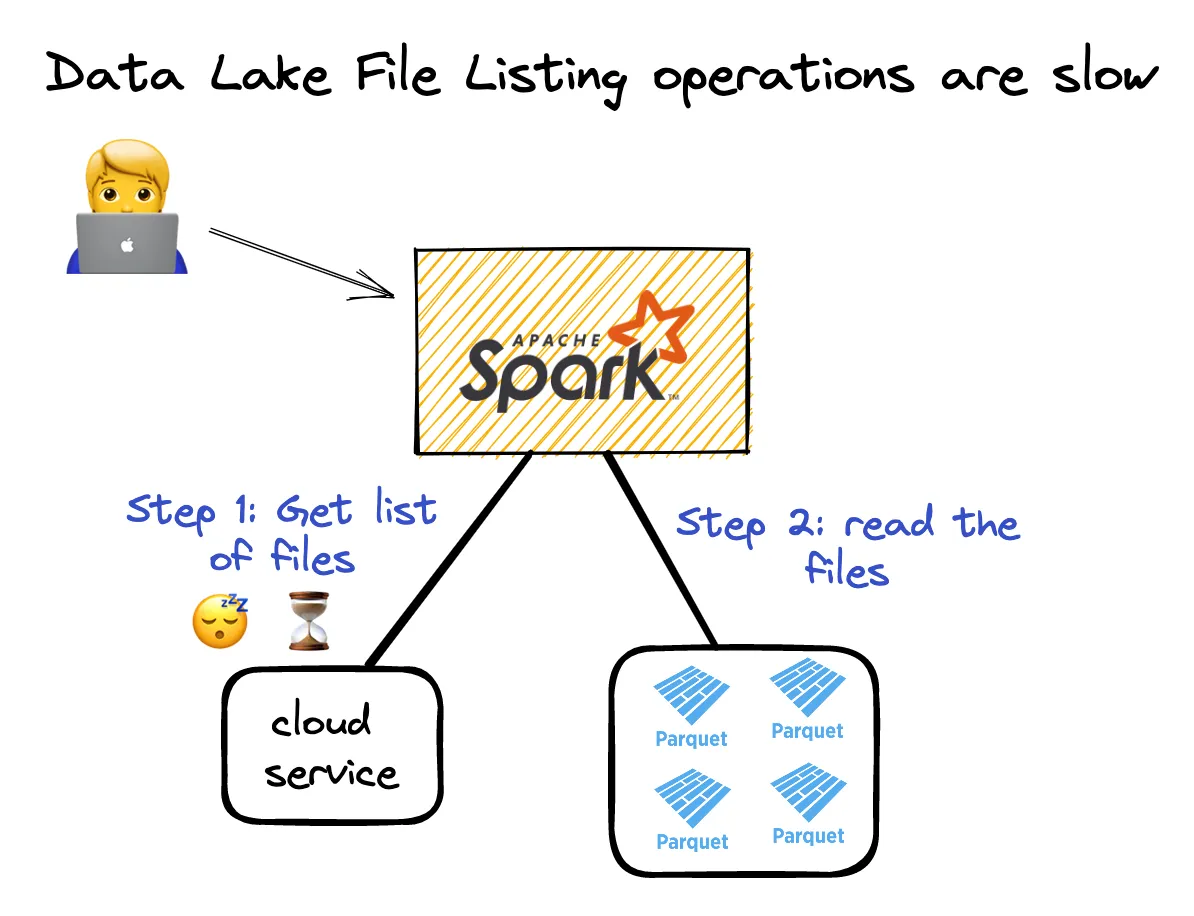
On a UNIX filesystem, listing files isn’t too expensive. File listing operations are slower for data in the cloud. Cloud-based file systems are key/value object stores, which aren’t similar to UNIX-like filesystems. Key value stores are slow at listing files.
Delta Lakes store the paths to Parquet files in the transaction log to avoid performing an expensive file listing. Delta Lake doesn’t need to list all Parquet files in the cloud object store to fetch their paths. It can just look up the file paths in the transaction log.
Cloud object stores are bad at listing files that are nested in directories. Files stored with Hive-style partitioning in cloud-based systems can require file listing operations that take minutes or hours to compute.
It’s better to rely on the transaction log to get the paths to files in a table instead of performing a file listing operation.
Delta Lake vs. Parquet: small file problem
Big data systems that are incrementally updated can create a lot of small files. The small file problem is particularly pronounced when incremental updates happen frequently and for Hive partitioned datasets.
Data processing engines don’t perform well when reading datasets with many small files. You typically want files that are between 64 MB and 1 GB. You don’t want tiny 1 KB files that require excessive I/O overhead.
Data practitioners will commonly want to compact the small files into larger files with a process referred to as “small file compaction” or “bin-packing”.
Suppose you have a dataset with 10,000 small files that are slow to query. You can compact these 10,000 small files into a dataset with 100 right-sized files.
If you’re working with a plain vanilla Parquet data lake, you need to write the small file compaction code yourself. With Delta Lake, you can simply run the OPTIMIZE command, and Delta Lake will handle the small file compaction for you.
ETL pipelines often process new files. With a plain vanilla Parquet lake, there are two types of new files: new data and old data that’s compacted into bigger files. You don’t want downstream systems to reprocess old data already processed. Delta Lake has a data_change=False flag that lets downstream systems distinguish between new data and new files that are just compacted versions of existing data. Delta Lake is much better for production ETL pipelines.
Delta Lake makes small file compaction easier than a plain vanilla Parquet table. See this blog post on small file compaction with OPTIMIZE to learn more.
Delta Lake vs. Parquet: ACID transactions
Databases support transactions, which prevent a host of data errors compared to data systems that don’t support transactions.
Parquet tables don’t support transactions, so they are easy to corrupt. Suppose you’re appending a large amount of data to an existing Parquet lake, and your cluster dies in the middle of the write operation. Then, you’ll have several partially written Parquet files in your table.
The partially written files will break any subsequent read operations. The compute engine will try to read in the corrupt files and error out. You’ll need to manually identify all the corrupted files and delete them to fix your lake. A corrupt table typically breaks a lot of data systems in an organization and requires an urgent hotfix - not fun.
Delta Lake supports transactions, so you’ll never corrupt a Delta Lake by a write operation that errors out midway through. If a cluster dies when writing to a Delta table, the Delta Lake will simply ignore the partially written files, and subsequent reads won’t break. Transactions also have a lot of other benefits, and this is just one example.
Delta Lake vs. Parquet: column pruning
Queries run faster if you can send less data to the computation cluster. Column-based file formats allow you to cherry-pick specific columns from a table, whereas row-based file formats require sending all the columns to the cluster.
Delta Lake and Parquet are columnar, so you can cherry-pick specific columns from a data set via column pruning (aka column projection). Column pruning isn’t an advantage for Delta Lake compared to Parquet because they support this feature. Delta Lake stores data in Parquet files under the hood.
However, column pruning isn’t possible with data stored in a row-based file format like CSV or JSON, so this is a significant performance benefit for Delta Lake compared to a row-based file format.
Delta Lake vs. Parquet: file skipping
Delta tables store metadata information about the underlying Parquet files in the transaction log. It’s quick to read the transaction log of a Delta table and figure out what files can be skipped.
Parquet files store metadata for row groups in the footer, but fetching all the footers and building the file-level metadata for the entire table is slow. It requires a file-listing operation, and we’ve already discussed how file-listing can be slow.
Parquet doesn’t support file-level skipping, but row-group filtering is possible.
Delta Lake vs. Parquet: predicate pushdown filtering
Parquet files have metadata statistics in the footer that can be leveraged by data processing engines to run queries more efficiently.
Sending less data to a computation cluster is a great way to make a query run faster. You can accomplish this by sending fewer columns or rows of data to the engine.
The Parquet file footer also contains min/max statistics for each column in the file (the min/max statistics are technically tracked for each row group, but let’s keep it simple). Depending on the query, you can skip an entire row group. For example, suppose you’re running a filtering operation and would like to find all values where col4=65. If there is a Parquet file with a max col4 value of 34, you know that file doesn’t have any relevant data for your query. You can skip it entirely.
The effectiveness of data skipping depends on how many files you can skip with your query. But this tactic can provide 10x - 100x speed gains, or more - it’s essential.
When you’re reading a single Parquet file, having the metadata in the Parquet file footer is fine. If you have 10,000 files, you don’t want to have to read in all the file footers, gather the statistics for the overall lake, and then run the query. That’s way too much overhead.
Delta Lake stores the metadata statistics in the transaction log, so the query engine doesn’t need to read all the individual files and gather the statistics before running a query. It’s way more efficient to fetch the statistics from the transaction log.
Delta Lake Z Order indexing
Skipping is much more efficient when the data is Z Ordered. More data can be skipped when similar data is co-located.
The Data & AI Summit talk on Why Delta Lake is the Best Storage Format for pandas analyses shows how Z Ordering data in a Delta table can significantly decrease the runtime of a query.
It’s easy to Z Order the data in a Delta table. It’s not easy to Z Order the data in a Parquet table. See the blog post on Delta Lake Z Order to learn more.
Delta Lake vs. Parquet: renaming columns
Parquet files are immutable, so you can’t modify the file to update the column name. If you want to change the column name, read it into a DataFrame, change the name, and then rewrite the entire file. Renaming a column can be an expensive computation.
Delta Lake abstracted the concept of physical column names and logical column names. The physical column name is the actual column name in the Parquet file. The logical column name is the column name humans use when referencing the column.
Delta Lake lets users quickly rename columns by changing the logical column name, a pure-metadata operation. It’s just a simple entry in the Delta transaction log.
There isn’t a quick way to update the column name of a Parquet table. You need to read all the data, rename the column, and then rewrite all the data. This is slow for big datasets.
Delta Lake vs. Parquet: dropping columns
Delta Lake also allows you to drop a column quickly. You can add an entry to the Delta transaction log and instruct Delta to ignore columns on future operations - it’s a pure metadata operation.
Parquet tables require that you read all the data, drop the column with a query engine, and then rewrite all the data. It’s an extensive computation for a relatively small operation.
See this blog post for more information on how to drop columns from Delta tables.
Delta Lake vs. Parquet: schema enforcement
You usually want to allow appending DataFrames with a schema that matches the existing table and to reject appends of DataFrames with schemas that don’t match.
With Parquet tables, you need to code this schema enforcement manually. You can append DataFrames with any schema to a Parquet table by default (unless they’re registered with a metastore and schema enforcement is provided via the metastore).
Delta Lakes have built-in schema enforcement, which saves you from costly errors that can corrupt your Delta Lake. See this post for more information about schema enforcement.
You can also bypass schema enforcement in Delta tables and change the schema of a table over time.
Delta Lake vs. Parquet: schema evolution
Sometimes, you’d like to add additional columns to your Delta Lake. Perhaps you rely on a data vendor, and they’ve added a new column to your data feed. You’d prefer not to rewrite all the existing data with a blank column so that you can add a new column to your table. You’d like a little schema flexibility. You’d just like to write the new data with the additional column and keep all the existing data as is.
Delta Lake allows for schema evolution so you can seamlessly add new columns to your dataset without running big computations. It’s another convenience feature that commonly comes in handy for real-world data applications. See this blog post for more information about schema evolution.
Suppose you append a DataFrame to a Parquet table with a mismatched schema. In that case, you must remember to set a specific option every time you read the table to ensure accurate results. Query engines usually take shortcuts when determining the schema of a Parquet table. They look at the schema of one file and just assume that all the other files have the same schema.
The engine consults the schema of all the files in a Parquet table when determining the schema of the overall table when you manually set a flag. Checking the schema of all the files is more computationally expensive, so it isn’t set by default. Delta Lake schema evolution is better than what’s offered by Parquet.
Delta Lake vs. Parquet: check constraints
You can also apply custom SQL checks to columns to ensure data appended to a table is a specified form.
Simply checking the schema of a string column might not be enough. You may also want to ensure that the string matches a certain regular expression pattern and that a column does not contain NULL values.
Parquet tables don’t support check constraints like Delta Lake does. See this blog post on Delta Lake Constraints and Checks to learn more.
Delta Lake vs. Parquet: versioned data
Delta tables can have many versions, and users can easily “time travel” between the different versions. Versioned data comes in handy for regulatory requirements, audit purposes, experimentation, and rolling back mistakes.
Versioned data also impacts how engines execute certain transactions. For example, when you “overwrite” a Delta table, you don’t physically remove files from storage. You simply mark the existing files as deleted, but don’t actually delete them. This is referred to as a “logical delete”.
Parquet tables don’t support versioned data. When you remove data from a Parquet table, you actually delete it from storage, which is referred to as a “physical deletes”.
Logical data operations are better because they are safer and allow for mistakes to be reversed. If you overwrite a Parquet table, it is an irreversible error (unless there is a separate mechanism backing up the data). It’s easy to undo an overwrite transaction in a Delta table.
See this blog post on Why PySpark append and overwrite operations are safer in Delta Lake than Parquet tables to learn more.
Delta Lake vs. Parquet: time travel
Versioned data also allows you to easily switch between different versions of your Delta Lake, which is referred to as time travel.
Time travel is useful in a variety of situations, as described in detail in the Delta Lake Time Travel post. Parquet tables don’t support time travel.
Delta Lake needs to keep some versions of the data around to support time travel, which adds an unnecessary storage cost if you don’t need historical data versions. Delta Lake makes it easy for you to optionally delete these legacy files.
Delta Lake vacuum command
You can delete legacy files with the Delta Lake vacuum command. For example, you can set the retention period to 30 days and run a vacuum command, which will allow you to delete all the unnecessary data that’s older than 30 days old.
It won’t delete all of the data older than 30 days old, of course. If there is data still required in the current version of the Delta Lake that’s “old,” it won’t get deleted.
Once you run a vacuum command, you can’t roll back to earlier versions of the Delta Lake. You can’t time travel back to a Delta Lake version from 60 days ago if you had set the retention period to 7 days and executed a vacuum command.
See this blog post for more information on the Delta Lake VACUUM command.
Delta Lake rollback
Delta Lake also makes it easy to reset your entire lake to an earlier version. Let’s say you inserted some data on a Wednesday and realized it was incorrect. You can easily roll back the entire Delta Lake to the state on Tuesday, effectively undoing all the mistakes you made on Wednesday.
You can’t roll back the Delta Lake to a version that’s farther back than the retention period if you’ve already run a vacuum command. That’s why you need to be careful before vacuuming your Delta Lake.
This blog post on How to Rollback a Delta Lake Table to a Previous Version with Restore.
Delta Lake vs. Parquet: deleting rows
You may want the ability to delete rows from your table, especially to comply with regulatory requirements like GDPR. Delta Lake makes it easy to perform a minimal delete operation, whereas it’s not easy to delete rows from a Parquet lake.
Suppose you have a user who would like their account deleted and all their data removed from your systems. You have some of their data stored in your table. Your table has 50,000 files, and this particular customer has data in 10 of those files.
Delta Lake makes it easy to run a delete command and will efficiently rewrite the ten impacted files without the customer data. Delta Lake also makes it easy to write a file that flags the rows that are deleted (deletion vectors), which makes this operation run even faster.
If you have a Parquet table, the only convenient operation is to read all the data, filter out the data for that particular user, and then rewrite the entire table. That will take a long time!
Manually identifying the 10 files that contain the user data and rewriting those specific files is tedious and error prone. It’s exactly the type of task that you’d like to delegate to your Lakehouse storage system rather than performing yourself.
Check out the blog post on How to Delete Rows from a Delta Lake table to learn more. Also make sure to check out the Delta Lake Deletion Vectors blog post to learn about how deletion operations can run much faster.
Delta Lake vs. Parquet: merge transactions
Delta Lake provides a powerful merge command that allows you to update rows, perform upserts, build slowly changing dimension tables, and more.
Delta Lake makes it easy to perform merge commands and efficiently updates the minimal number of files under the hood, similar to the efficient implementation of the delete command.
If you work with a Parquet table, you don’t have any access to a merge command. You need to implement all the low level merge details yourself, which is challenging and time consuming.
See the Delta Lake Merge blog post and how it makes the data manipulation language operations (INSERT, UPDATE, and DELETE) easier.
Other advantages of Delta Lake tables
Delta Lake has many other advantages over Parquet tables that aren’t discussed in this article, but you can check out these posts to learn more:
- How Delta Lake uses metadata to make certain aggregations much faster
- How to use Delta Lake generated columns
- Delta Lake Change Data Feed (CDF)
Conclusion
This article has shown you how Delta Lakes are generally better than Parquet tables. Delta Lakes make it easy to perform common data operations like dropping columns, renaming columns, deleting rows, and DML operations. Delta Lakes also support transactions and schema enforcement, so it’s much less likely you’ll corrupt your table. Delta Lake abstract the file metadata to a transaction log and support Z Ordering, so you can run queries faster.
Parquet lakes are still useful when you’re interfacing with systems that don’t support Delta Lake. You may need to convert a Delta Lake to a Parquet lake if a downstream system is unable to read the Delta Lake format. Delta tables store data in Parquet files, so it’s easy to convert from a Delta table to a Parquet table. Reading Delta tables with other systems is a nuanced topic, but many Delta Lake connectors have been built, so it’s unlikely that you cannot read a Delta talbe with your query engine of choice.
See this blog post to learn more about the growing Delta Lake connector ecosystem.