Apache Flink Source Connector for Delta Lake tables
We are excited to announce the release of Delta Connectors 0.5.0, which introduces the new Flink/Delta Source Connector on Apache Flink™ 1.13 that can read directly from Delta tables using Flink’s DataStream API. Both the Flink/Delta Source and Sink connectors are now available as one JVM library that provides the ability to read and write data from Apache Flink applications to Delta tables using the Delta Standalone JVM Library. The Flink/Delta Source Connector supports reading data from Delta tables into Flink for both batch and streaming processing.
Native Flink Delta Lake Source Connector
The Flink/Delta Source Connector is built on Flink’s new Unified Source Interface API, which was introduced in version 1.12 for building source connectors. Our connector uses low-level elements of the original File Source in addition to logic specific for reading Delta tables, such as reading the Delta table log.
Work modes
Flink/Delta Source Connector can work in one of two modes, Bounded (i.e. batch) or Continuous (i.e. streaming).
-
Bounded
This mode is mainly used for batch jobs and provides the ability to read the full data load of the latest version of the Delta table or load a specific snapshot version.
-
Continuous
This mode is used for streaming jobs, where in addition to reading the Delta table contents for a specific snapshot version, it continuously checks the Delta table for new updates and versions. It can also read changes only.
Flink periodically takes persistent snapshots of all the states and stores them in durable storage such as a distributed file system. In the event of a failure, Flink can restore the complete state of the application and resume processing from the last successful checkpoint.
Schema discovery
Flink Delta Source connector scans the Delta table log to discover columns and column types. It supports both reading all columns or a specified collection of columns using the Delta Source builder method. In both cases, the connector will discover the Delta data types for the table columns and will convert them to the corresponding Flink data types. The connector will automatically detect the partition columns using the Delta table log without any additional configuration needed.
Please see the documentation and examples for details.
Architecture
The Delta Source Connector has implemented the core components of Flink’s Unified Source Interface architecture. The connector provides Delta-specific implementations for interfaces such as Source and SplitEnumerator. In addition, it reuses low-level components from Flink’s File system support and Filink’s File Source, such as File Readers and Split assigners.
Unified Source Interface
Every Flink Data Source has three core components that support reading data from batch and streaming sources in a unified way.
-
Splits
This is the smallest unit of work that a source connector consumes, distributes the work, and parallelizes reading data from the source. A Split can be an entire file, a file block, a Kafka partition, or others.
-
SourceReader
SourceReader requests Splits and processes them by reading the Split from the data source. An example would be SourceReader sending a request to read a file or a log partition. SourceReaders run in parallel on the Task Managers and therefore produce the parallel stream of events/records.
-
SplitEnumerator
The SpltEnumerator creates the Splits and assigns them to the SourceReaders when they request the Splits. It runs as a single instance on the Job Manager process and maintains the list of assigned and pending Splits for a given data source. It is responsible for balancing the Splits across various SourceReaders that are running in parallel.
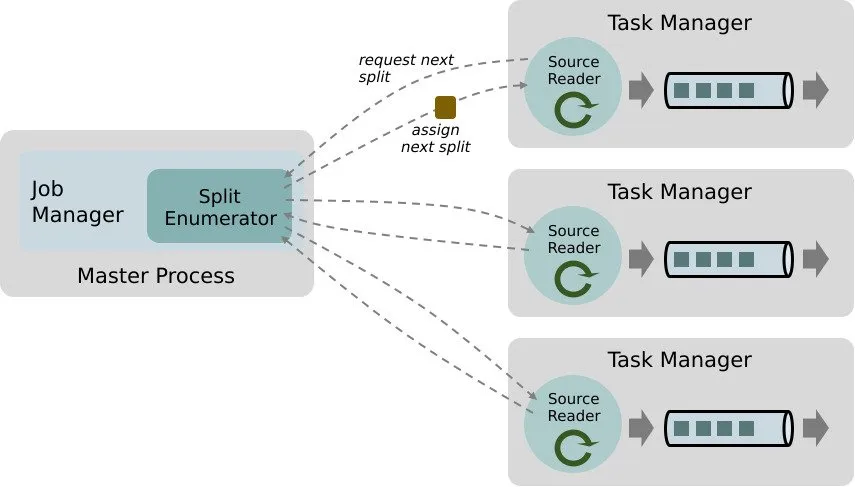
Flink’s Source class is an API entry point that combines all the above three components together. Please see Flink’s documentation for more details.
Source initialization
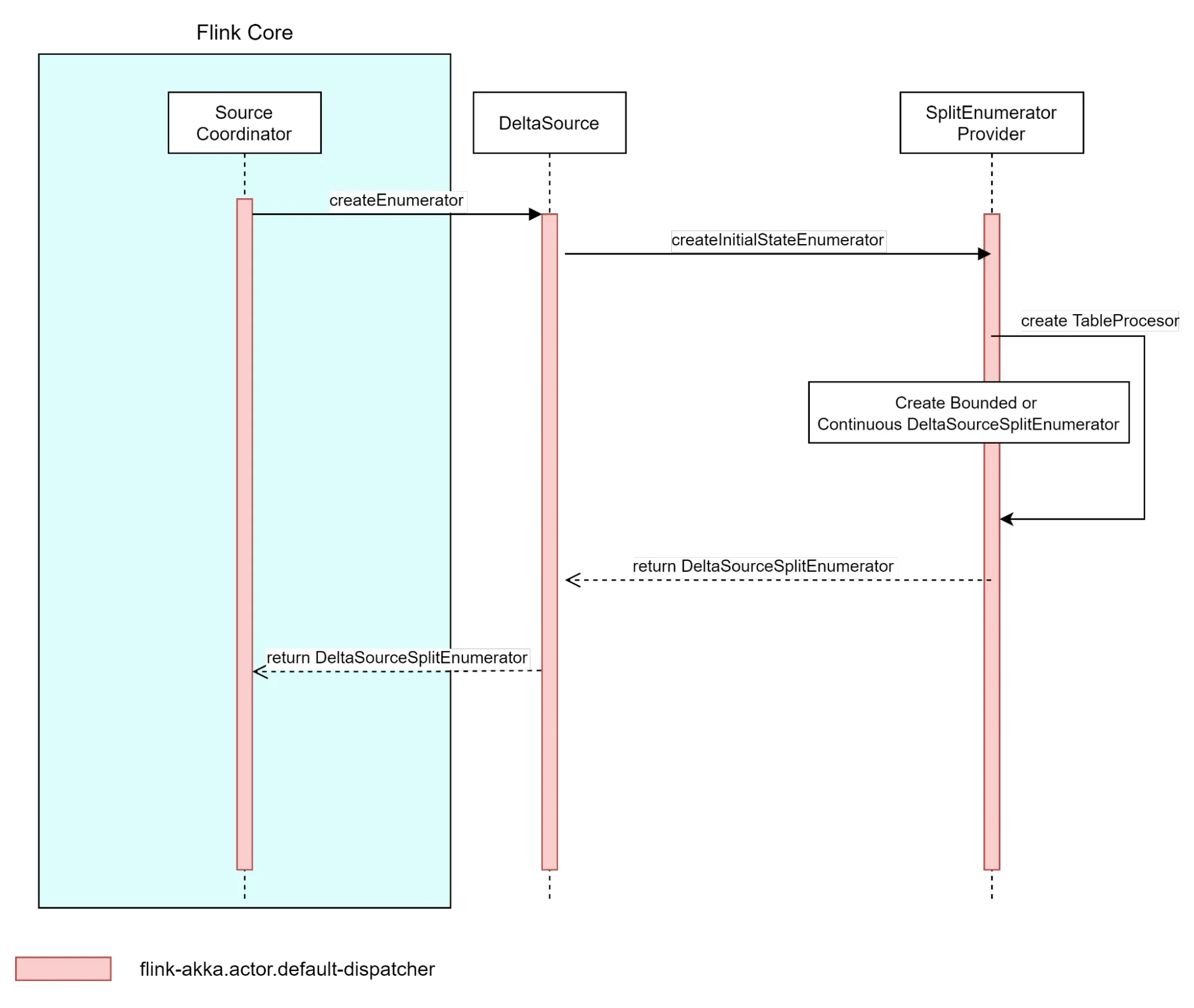
The Source interface, which is implemented by DeltaSource class, is an entry point for Flink’s runtime. The API is used by Flink’s SourceCoordinator, which uses it to initialize the Source instance. The initialization involves creating a SplitEnumerator and, in the case of disaster recovery, recreating it from a previously checkpointed state. Following that, file readers are also created during the source initialization phase.
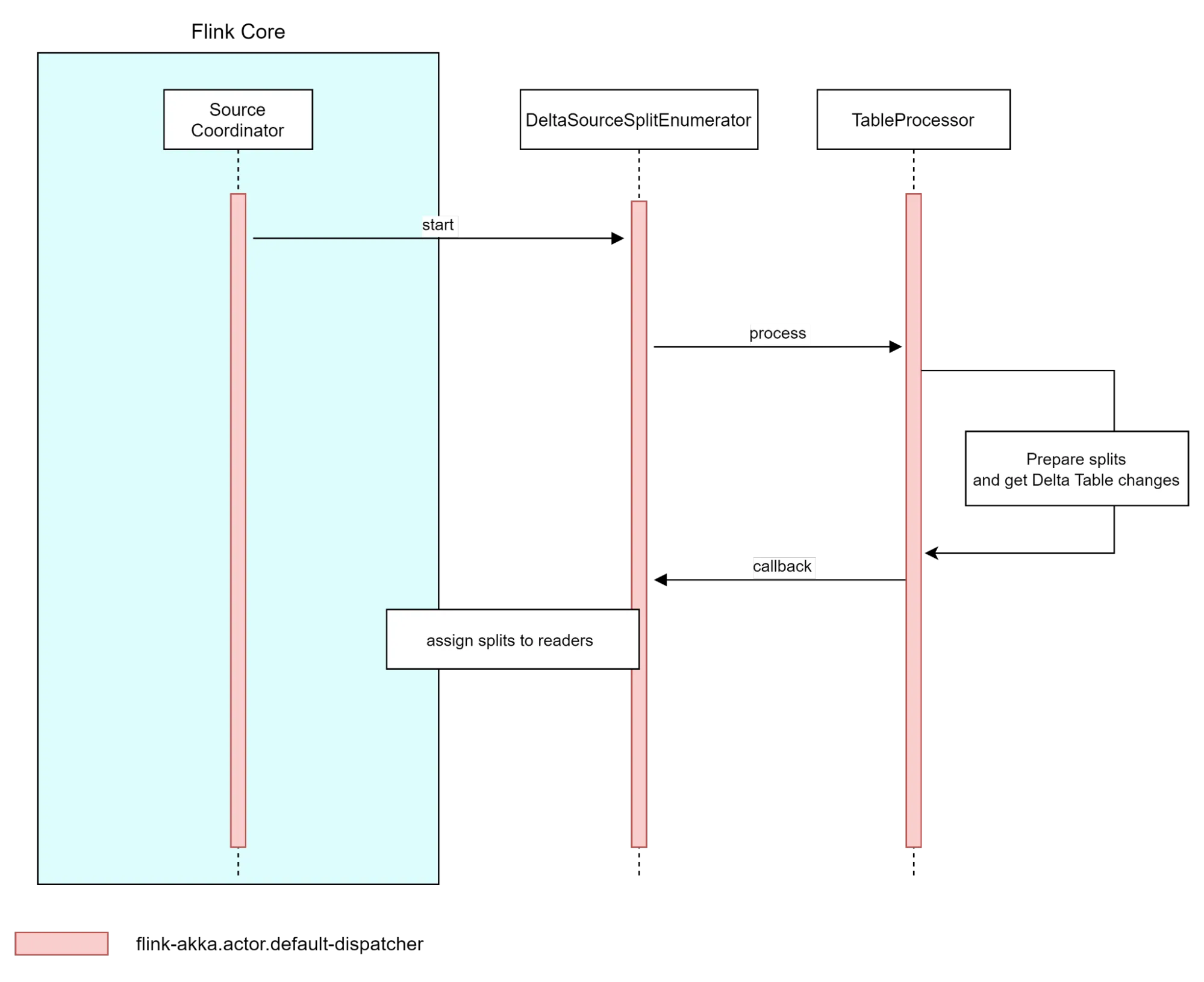
Delta Source instance uses SplitEnumeratorProvider to construct a concrete enumerator implementation based on used source options. The SplitEnumeratorProvider creates an instance of what we call a TableProcessor that acts like a bridge between Flink and Delta table log. TableProcesor implementation provides an entry point for Delta table snapshot and table changes that can be later converted to Splits and assigned to file readers by DeltaSourceSplitEnumerator
With the creation of the DeltaSourceSplitEnumerator, Flink can process the data via the TableProcessor, prepare the splits and get any Delta table changes prior to assigning the splits to the readers.
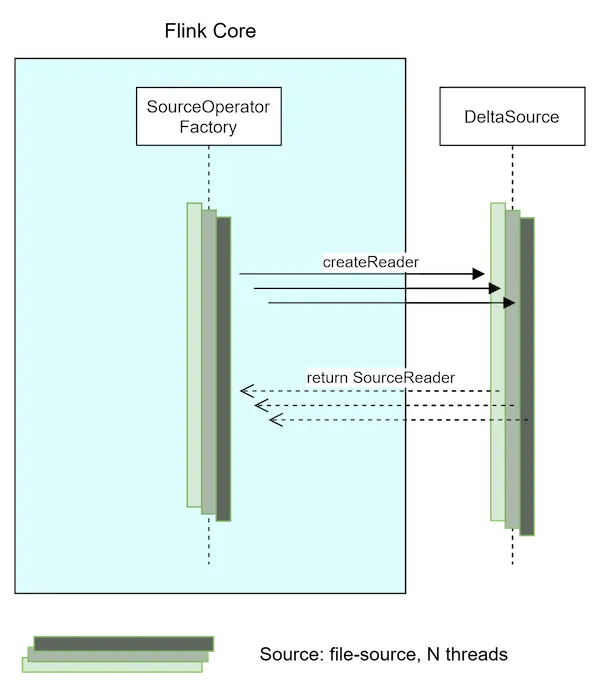
SourceReader Creation
Each SourceReader is created by a separate thread and the number of source readers created by Flink is dictated by the parallelism level of the source or the entire job.
Source Start
Newly created SourceReaders (each on its own thread) send Split Requests through Flink Core to SplitEnumerator in order to manifest their readiness to process new data. SplitEnumerator responds to these requests by assigning new splits to the readers by calling sourceReaderContext::assignSplit method. Then that split is assigned to the SourceReader by calling SourceReader::addSplits(List<Split>) method by Flink Core.
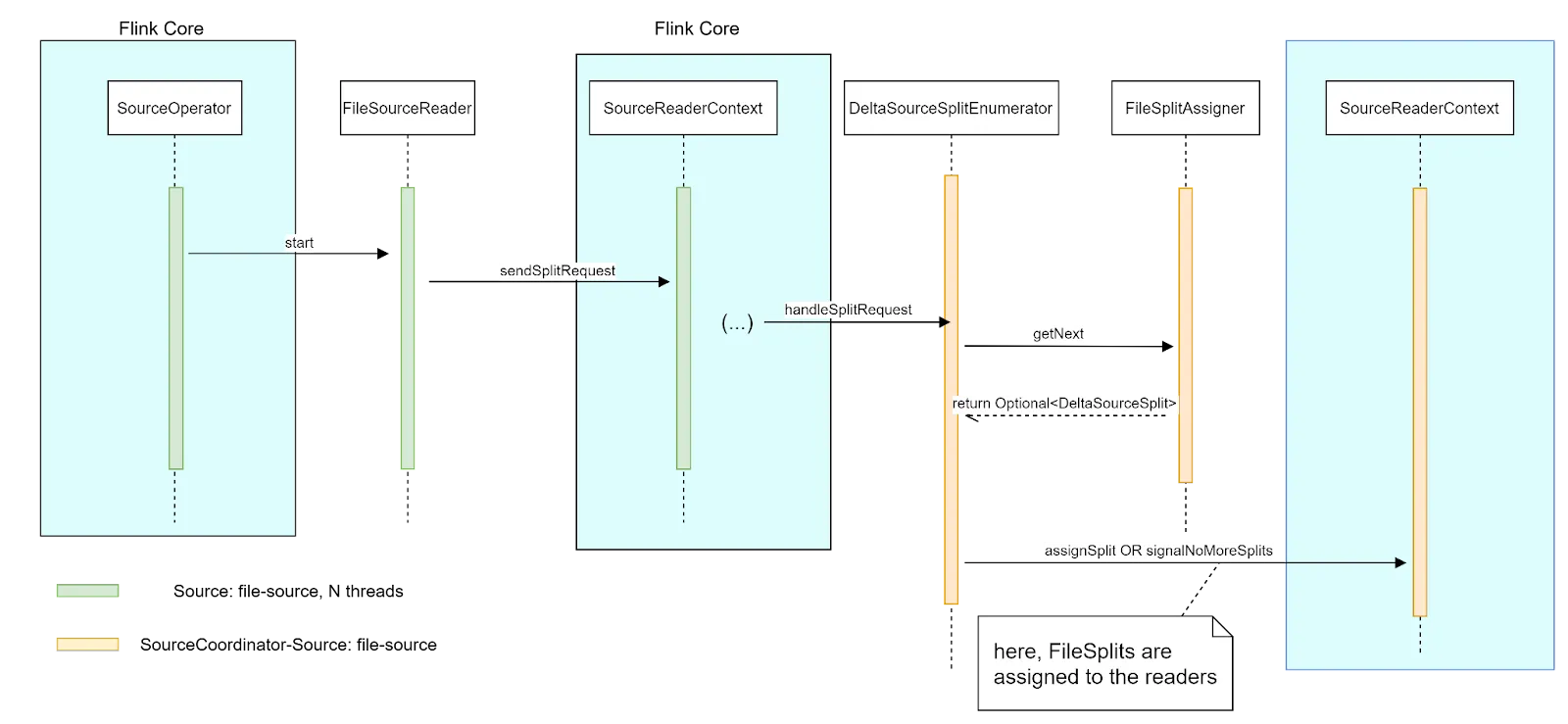
More detailed information can be found in Delta Connector Design Document.
Implementation - Reading data from Delta Lake tables into Flink
The Flink/Delta Lake Connector is a JVM library to read and write data from Apache Flink applications to Delta Lake tables utilizing the Delta Standalone JVM library and includes both the Source and Sink connectors. This section focuses on the Source connector and provides examples to read data directly from Delta Lake into Flink for both batch (bounded) and streaming (continuous) modes. Please see #110 for more information.
The Flink/Delta Source is designed to work with 1.13.0 <= Flink <= 1.14.5 and provides exactly-once delivery guarantees. This connector is dependent on the following packages:
delta-standaloneflink-parquetflink-table-commonhadoop-client
Please refer to the linked build file examples for maven and sbt.
Batch (or Bounded) Mode
- Reads all columns from a latest version of a Delta table
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.hadoop.conf.Configuration;
public DataStream<RowData> createBoundedDeltaSourceAllColumns(
StreamExecutionEnvironment env,
String deltaTablePath) {
DeltaSource<RowData> deltaSource = DeltaSource
.forBoundedRowData(
new Path(deltaTablePath),
new Configuration())
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}- Reads all columns from a specific historical version of a Delta table using Time Travel
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.hadoop.conf.Configuration;
public DataStream<RowData> createBoundedDeltaSourceWithTimeTravel(
StreamExecutionEnvironment env,
String deltaTablePath) {
DeltaSource<RowData> deltaSource = DeltaSource
.forBoundedRowData(
new Path(deltaTablePath),
new Configuration())
// could also use `.versionAsOf(314159)`
.timestampAsOf("2022-06-28 04:55:00")
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}- Reads user-defined columns from the latest version of a Delta table
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.hadoop.conf.Configuration;
public DataStream<RowData> createBoundedDeltaSourceUserColumns(
StreamExecutionEnvironment env,
String deltaTablePath,
String[] columnNames) {
DeltaSource<RowData> deltaSource = DeltaSource
.forBoundedRowData(
new Path(deltaTablePath),
new Configuration())
.columnNames(columnNames)
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}Streaming (or Continuous) Mode
- Reads all columns from Delta table from a historical version. Using Delta’s Time Travel, it loads all changes at and after the historical version and not the the full table state.
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.hadoop.conf.Configuration;
org.apache.flink.streaming.api.functions.sink.filesystem.DeltaBulkPartWriter
public DataStream<RowData> createContinuousDeltaSourceWithTimeTravel(
StreamExecutionEnvironment env,
String deltaTablePath) {
DeltaSource<RowData> deltaSource = DeltaSource
.forContinuousRowData(
new Path(deltaTablePath),
new Configuration())
// could also use `.startingVersion(314159)`
.startingTimestamp("2022-06-28 04:55:00")
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}- Reads all columns from the latest version of Delta table and continuously monitors for table updates
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.hadoop.conf.Configuration;
public DataStream<RowData> createContinuousDeltaSourceAllColumns(
StreamExecutionEnvironment env,
String deltaTablePath) {
DeltaSource<RowData> deltaSource = DeltaSource
.forContinuousRowData(
new Path(deltaTablePath),
new Configuration())
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}- Reads only user-defined columns from the latest version of the Delta table and continuously monitors for table updates.
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.hadoop.conf.Configuration;
public DataStream<RowData> createContinuousDeltaSourceUserColumns(
StreamExecutionEnvironment env,
String deltaTablePath,
String[] columnNames) {
DeltaSource<RowData> deltaSource = DeltaSource
.forContinuousRowData(
new Path(deltaTablePath),
new Configuration())
.columnNames(columnNames)
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}More information on how to build and test is here.
What’s Next?
As noted in Writing to Delta Lake from Apache Flink, we have worked together to create the initial Flink/Delta sink and now Flink/Delta source. But they currently only support the Flink DataStream API. Support for Flink Table API / SQL, along with Flink Catalog’s implementation for storing Delta table’s metadata in an external metastore, are planned as noted in Extend Delta connector for Apache Flink’s Table APIs (#238).
How can you help?
We’re always excited to work with current and new community members. If you’re interested in helping the Delta Lake project, please join our community today through many forums, including GitHub, Slack, Twitter, LinkedIn, YouTube, and Google Groups.

 Scott Sandre
Scott Sandre