Delta Lake Upsert
By Avril Aysha
This article will show you how to perform Upsert operations with Delta Lake.
When you’re working with production data at scale, you often need to update records within a large dataset. Because your data is large and resources are limited, you want to do this without reprocessing everything from scratch.
Delta Lake upserts allow you to insert, update, or delete records in one operation, without having to rewrite the entire dataset. This makes it easier and cheaper to keep your data current and accurate.
In this article, you’ll learn how to perform upserts in Delta Lake both with Spark and with delta-rs (no Spark dependencies).
Upserts are especially useful when:
- You regularly need to make small changes to a big table
- You are implementing slowly changing dimensions in a data warehouse.
- You want to ensure a single source of truth with consistent and accurate data.
Let’s jump into the details of performing upserts with Delta Lake.
Why Use Upserts in Delta Lake?
Traditional data lakes use immutable file formats like Parquet. Immutable file formats are great for preventing data corruption. They are very inefficient for making small changes to a large dataset.
Suppose you have a dataset with 50 million rows of data. Now one of your data points changes (someone changes their address or makes a purchase, for example) and this needs to be updated in the main dataset. You also need to insert a new row. In a dataset stored as Parquet this will require either: (1) an entire rewrite of all 50 million rows or (2) storing updates in many small files, leading to the Small File Problem. Either way, this will be slow and costly.
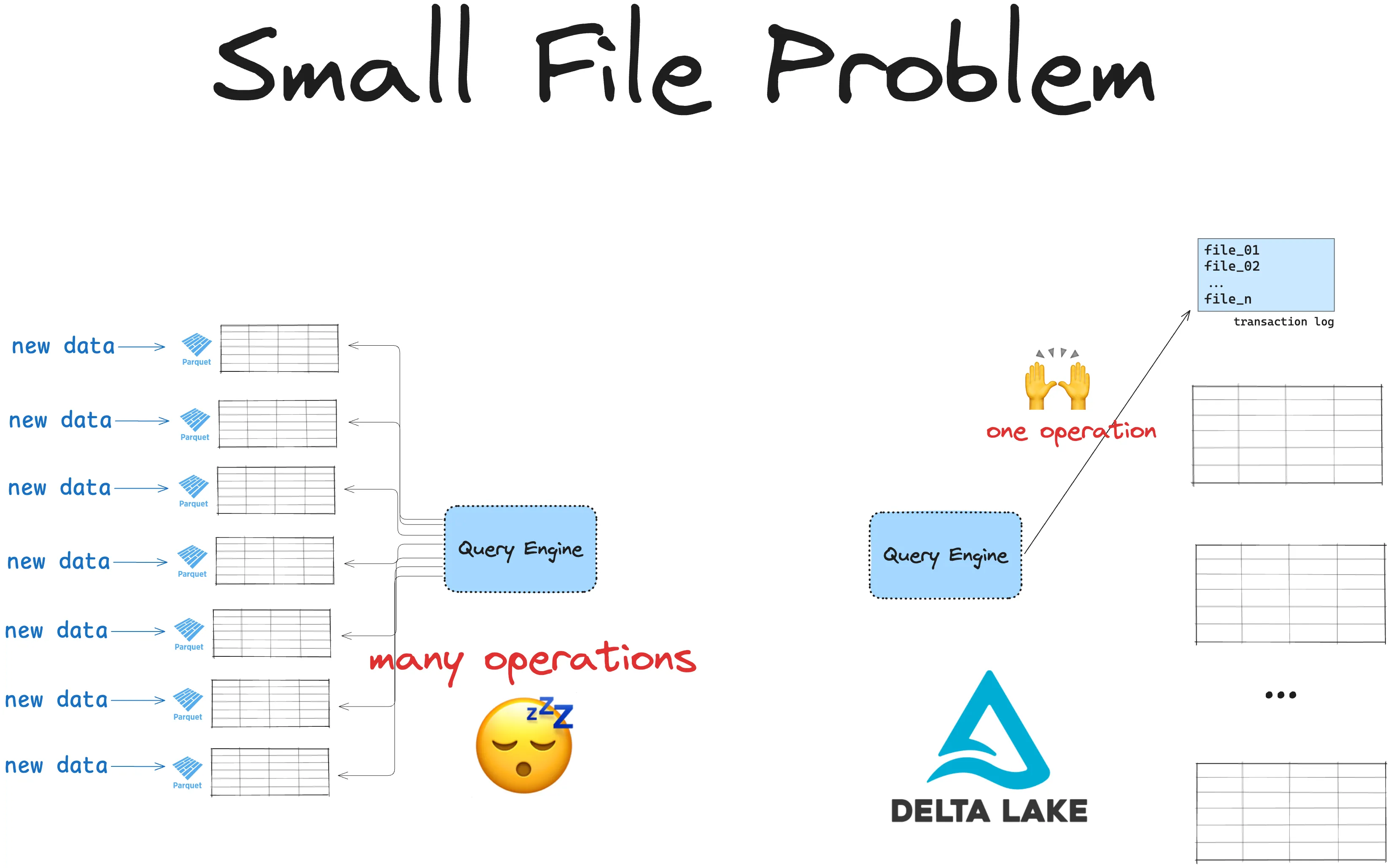
Delta Lake allows you to do this in a single small operation. Instead of rewriting all the data, Delta Lake registers your upsert operation as a simple change to the Delta Lake transaction log. This is quick and simple. The operation can complete quickly and you do not need to rewrite all the data again. You can also easily inspect previous versions when you need them.
Let’s do a quick benchmarking exercise to see this in action.
Benchmark Delta Lake vs Parquet for Upserts
Let’s start by reading in a reasonably large dataset stored as Parquet:
# read a parquet file
df_parq = spark.read.format("parquet").load("tmp/data.parquet")And inspect the number of rows:
> df_parq.count()
53311644
> df_parq.show(3)
+--------------------+--------------------+------+--------------------+
| id| names|emails| categories|
+--------------------+--------------------+------+--------------------+
|08ff39b22bae03010...|{Mount Boyd, null...| NULL| {mountain, null}|
|08ff39ba2b6909990...|{Erickson Glacier...| NULL|{landmark_and_his...|
|08ff39b209b20c1b0...|{Mount Cromie, nu...| NULL| {mountain, null}|
+--------------------+--------------------+------+--------------------+This dataset has more than 53 million rows of data. Each row is a registered place with names, emails and relevant categories.
Let’s update the emails field for the first row:
from pyspark.sql.functions import col, when
df_parq = df_parq.withColumn(
"emails",
when(
df_parq.id == "08ff39b22bae03010337585ac81e0535",
"email@address.com"
).otherwise(df.emails)
)Now let’s insert a new row to the dataset:
# create new row
new_row = spark.createDataFrame([('1222355', 'Cool Place', 'another_email@address.com', "Recreational")], df_parq.columns)
# append to dataframe
df_parq = df_parq.union(new_row)Parquet is an immutable file format so we cannot overwrite or amend our existing file. The only way to store these changes is to write the entire DataFrame out to a new Parquet file.
> %%time
> df_parq.write.format("parquet").save("tmp/new_data.parquet")
CPU times: user 9.09 ms, sys: 5.65 ms, total: 14.7 ms
Wall time: 28.8 sThis took more than 28 seconds on an M1 Macbook Pro with 8 cores. That’s quite slow for a single upsert operation.
Not only that, but we now have two large files on disk.
> ! du -h tmp/*
2.8G tmp/data.parquet
2.8G tmp/new_data.parquetLet’s see what this would look like with Delta Lake.
Load your target Delta table:
target_table = DeltaTable.forPath(spark, "tmp/delta_table")
df = spark.read.format("delta").load("tmp/delta_table")And then let’s add our new data with one update and one new record:
new_data = [
("08f3915108b7651b0395cf706df3eafb", "{Pateo do Sado, null, null}", "email@address.com", "{pizza_restaurant, [portuguese_restaurant, bar]}"), # Update
("1112222333355", "Cool Place", "another_email@address.com", "Recreational") # Insert
]
source_df = spark.createDataFrame(new_data, df.columns)Now let’s perform the upsert in a single operation using the MERGE command:
%%time
# Perform the upsert (MERGE)
target_table.alias("target") \
.merge(
source_df.alias("source"),
"target.id = source.id"
) \
.whenMatchedUpdate(set={
"names": "source.names",
"emails": "source.emails"
}) \
.whenNotMatchedInsert(values={
"id": "source.id",
"names": "source.names",
"emails": "source.emails",
"categories": "source.categories"
}) \
.execute()
CPU times: user 4.77 ms, sys: 2.64 ms, total: 7.41 ms
Wall time: 13.6 sThis is much faster.
Let’s look at the files on disk:
! du -h tmp/*
0B tmp/delta_table/_delta_log/_commits
32K tmp/delta_table/_delta_log
3.1G tmp/delta_tableDelta Lake does not duplicate data unnecessarily. This is much more efficient.
The Delta table is marginally larger than the Parquet data on disk. This makes sense because we are storing additional metadata which makes our queries faster and our data less corruptible.
Let’s break this process down using a step-by-step example with simple code and data.
Getting Started with Delta Lake Upsert
An upsert is a specific instance of a MERGE operation. You have two (or more) datasets and you need to merge data points from one dataset into another: you need to update an existing row and insert a new one.
The MERGE statement in Delta Lake is designed to handle upserts. It lets you combine insert, update, and delete actions within a single query.
The basic syntax for a Delta Lake MERGE operation is as follows:
target_table.alias("target") \
.merge(source_table.alias("source"), "condition") \
.whenMatchedUpdate(set={"target_column": "source_column"}) \
.whenNotMatchedInsert(values={"target_column": "source_column"}) \
.execute()Here’s a breakdown:
target_tableis the table where you want to perform the upsert.source_tableis the table with the new data.conditionspecifies how the two tables are joined, often using a unique identifier.whenMatchedUpdateallows you to update rows intarget_tablethat match rows insource_table.whenNotMatchedInsertlets you insert rows intotarget_tablethat don’t have matches insource_table.
Now let’s look at a real code example.
Example: Upsert Data in Delta Lake
Let’s say you have a customer Delta table with records that you need to keep updated based on incoming data in a new_data DataFrame.
1. Define Your Target Delta Table
First, make sure you have a Delta table to act as the target. If it doesn’t exist, create it.
from delta.tables import DeltaTable
# Create a sample target Delta table
data = [(1, "Alice", "2023-01-01"), (2, "Bob", "2023-01-01")]
columns = ["customer_id", "name", "last_update"]
df = spark.createDataFrame(data, columns)
df.write.format("delta").mode("overwrite").save("/delta/customer")
target_table = DeltaTable.forPath(spark, "/delta/customer")2. Create the Source DataFrame (New Data)
Here’s the new data that you want to upsert.
# new data with one update and one new record
new_data = [
(1, "Alice", "2023-02-01"), # Update: Alice's last_update changes
(3, "Charlie", "2023-02-01") # Insert: new record for Charlie
]
new_columns = ["customer_id", "name", "last_update"]
source_df = spark.createDataFrame(new_data, new_columns)3. Perform the MERGE Operation
With both target_table and source_df set up, you can now run the MERGE statement.
# Perform the upsert (MERGE)
target_table.alias("target") \
.merge(
source_df.alias("source"),
"target.customer_id = source.customer_id"
) \
.whenMatchedUpdate(set={
"name": "source.name",
"last_update": "source.last_update"
}) \
.whenNotMatchedInsert(values={
"customer_id": "source.customer_id",
"name": "source.name",
"last_update": "source.last_update"
}) \
.execute()This operation automatically creates a new transaction in the Delta Lake transaction log.
4. Verify the Results
After performing the upsert, you can view the updated customer Delta table.
> # read the updated Delta table to verify
> updated_df = spark.read.format("delta").load("/delta/customer")
> updated_df.show()
+-----------+-------+-----------+
|customer_id| name|last_update|
+-----------+-------+-----------+
| 1| Alice| 2023-02-01|
| 3|Charlie| 2023-02-01|
| 2| Bob| 2023-01-01|
+-----------+-------+-----------+The result shows that Alice’s last_update has changed and that Charlie’s record was added as a new entry. Great work!
5. Use Time Travel to Inspect Previous Versions
Delta Lake’s time travel functionality lets you go back to previous versions of your data.
> # travel back to original version if needed
> original_df = spark.read.format("delta").option("versionAsOf", 0).load("tmp/customer")
> original_df.show()
+-----------+-----+-----------+
|customer_id| name|last_update|
+-----------+-----+-----------+
| 1|Alice| 2023-01-01|
| 2| Bob| 2023-01-01|
+-----------+-----+-----------+This makes it easy to recover data when needed. Read more in the Delta Lake Time Travel post.
Delta Lake Upsert with custom MERGE Conditions
You can customize your upserts in Delta Lake using conditional logic. This gives you more control over how updates and inserts happen. Here are a few ways you might customize it:
Selective Updates: Apply updates only if a certain condition is met.
.whenMatchedUpdate(
condition="source.last_update > target.last_update",
set={"name": "source.name",
"last_update": "source.last_update"}
)Conditional Inserts: Insert records based on specific criteria.
.whenNotMatchedInsert(
condition="source.status = 'active'",
values={"customer_id": "source.customer_id", "name": "source.name",
"last_update": "source.last_update"}
)Read more in the Delta Lake Merge post.
Delta Lake Upsert with delta-rs
You don’t need to use Spark to perform upsert operations with Delta Lake. You can use non-Spark engines like PyArrow, pandas, Polars and Daft as well. In this case, you will use delta-rs: the Rust implementation of Delta Lake.
Here’s an example of an upsert operation with Delta Lake using delta-rs:
import pyarrow as pa
from deltalake import DeltaTable, write_deltalake
target_data = pa.table({"x": [1, 2, 3], "y": [4, 5, 6]})
write_deltalake("tmp_table", target_data)
dt = DeltaTable("tmp_table")
source_data = pa.table({"x": [2, 3, 5], "y": [5, 8, 11]})
(
dt.merge(
source=source_data,
predicate="target.x = source.x",
source_alias="source",
target_alias="target")
.when_matched_update(
updates={"x": "source.x", "y":"source.y"})
.when_not_matched_insert(
updates={"x": "source.x", "y":"source.y"})
.execute()
)Read more about using Delta Lake without Spark dependencies in the Delta Lake without Spark post.
Best Practices for Delta Lake Upserts
Here are some best practices to consider when running your Delta Lake upsert operations:
- Optimize Table Performance: Periodically optimize and vacuum your Delta tables to improve performance and reduce storage costs. Read more in the Delta Lake Optimize post.
- Enable Z-Ordering or Liquid Clustering: For large tables, consider Z-Ordering on frequently queried columns or enabling Liquid Clustering. This can help to reduce read time. Read more in the Delta Lake Z Order post.
- Use Primary Keys in Conditions: When possible, use a unique identifier in the
MERGEcondition to prevent unintentional duplicates.
Using Delta Lake for Upsert Operations
Delta Lake makes it easy to perform upserts in a reliable and efficient way. This allows you to manage incremental updates in your data lake at scale without having to worry about data corruption or performance bottlenecks. Delta Lake upserts work well for both batch and streaming workloads.