Delta Lake - State of the Project - Part 2
This is part 2 of a 2 part blog series:
Part I: Delta Lake - State of the Project
Part II: Delta Lake - State of the Project
The future is interoperable
In our first State of the Project blog, we discussed the impressive growth and activity in the Delta Lake community and the feature innovations that we’ve released, like Liquid clustering and Deletion Vectors. In part 2, we’re going to dig a bit deeper into some of the differentiating features of the format, specifically Interoperability and Performance.
Interoperability across engines, connectors, and formats
Delta UniForm: Easy interoperability across all formats
One of the key challenges that organizations face when adopting the open data lakehouse is selecting the optimal format for their data. Among the available options, Linux Foundation Delta Lake, Apache Iceberg, and Apache Hudi are all excellent storage formats that enable data democratization and interoperability. Any of these formats is better than putting your data into a proprietary format. However, choosing a single storage format to standardize on can be a daunting task, which can result in decision fatigue and fear of irreversible consequences. But what if you didn’t have to choose just one?
In 2023, we announced a new initiative called Delta Lake Universal Format (UniForm), which offers a simple, easy-to-implement, seamless unification of table formats without creating additional data copies or silos. UniForm takes advantage of the fact that Delta Lake, Iceberg, and Hudi are all built on Apache Parquet data files. The main difference among the formats is in the metadata - the metadata for all three formats serves the same purpose and contains overlapping sets of information. When enabled on Delta tables, UniForm automatically writes metadata of other formats (only Iceberg released today, but our community is adding support for Hudi). This allows you to use Delta Lake-compliant engines and Iceberg-compliant engines without having to manually convert your data, or maintain multiple copies of the data in different formats.
In addition, you can also do a one-time, zero-copy, in-place conversion of Iceberg tables to Delta tables.
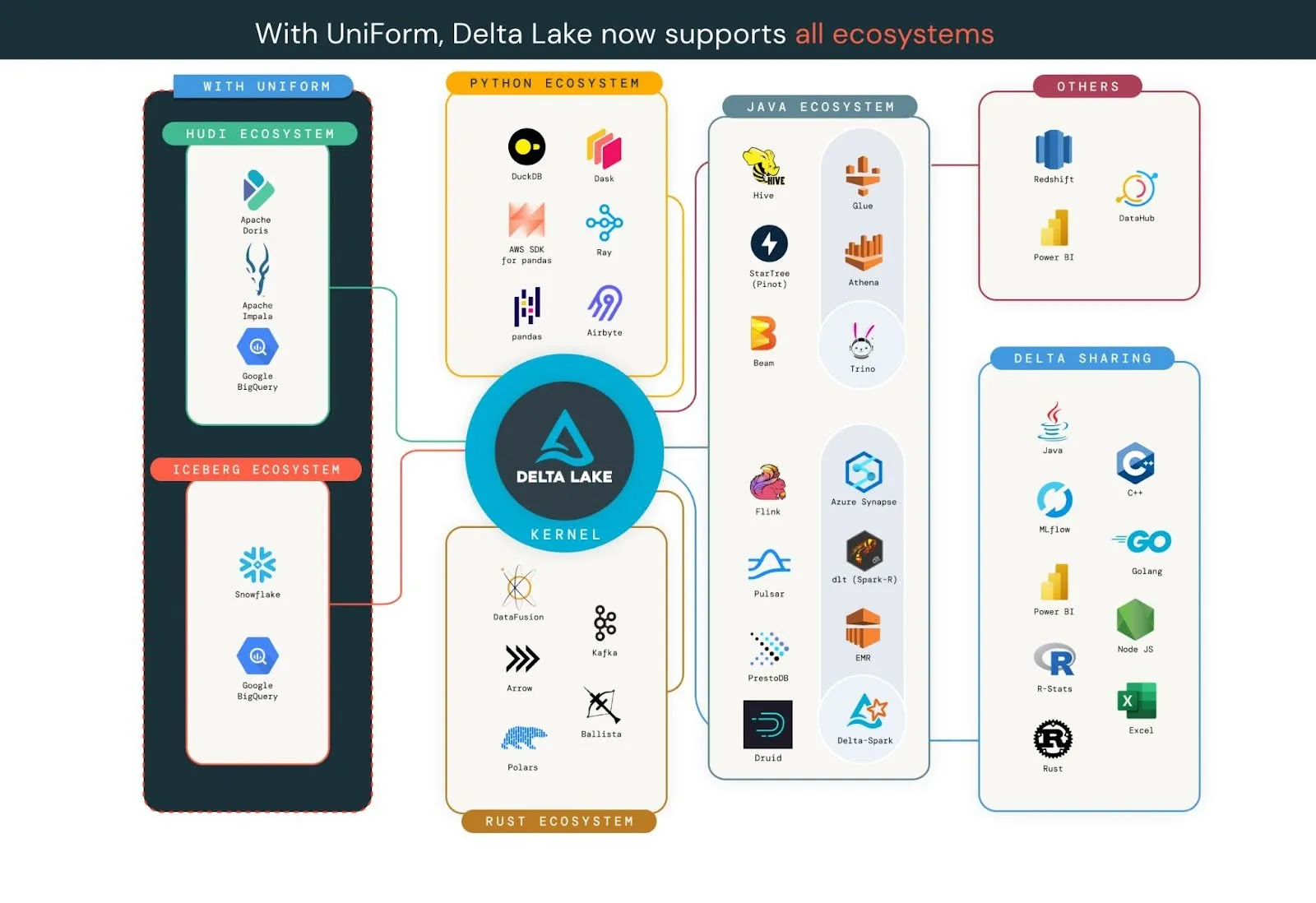
Delta Kernel: Simplifying the connector ecosystem
While we are adding protocol features to the Delta format at an ever-increasing pace, we must ensure that all systems can continue to operate on Delta tables. The Delta connector ecosystem is already expansive and our goal is to keep expanding and enhancing all their capabilities to make it as easy as possible to use Delta tables anywhere in your data stack. However, until last year, connector developers often needed to understand all the details of the Delta protocol to implement all the protocol features correctly. This definitely makes it challenging for the ecosystem to keep up with the pace of innovation. Based on the community feedback, in 2023, we started a new initiative called Delta Kernel.
The goal of the Delta Kernel project is to simplify the process of building and maintaining Delta Lake connectors. Delta Kernel is a library that abstracts out all the protocol details behind simple, stable APIs. Connectors built using the Kernel library only need to update to the latest version to get the latest Delta protocol support. The two key features of the Kernel are:
- Pluggable architecture - While we want to hide all the protocol-level details from the connector, we do not want to prevent any engine from making customizations to their Delta connector. Kernel provides additional APIs that allow custom component implementations to be plugged in. For example, the Kernel library provides an out-of-box “default” implementation for reading the underlying Parquet files. A connector can choose to use that or replace it with its own engine-native Parquet reader for better performance. This provides the right balance of simplicity and customizability.
- Multi-language support - We are building the Delta Kernel in two languages: Java (for the JVM-based engines) and Rust (for engines built in Rust, C, C++, Python or any language that interoperates with Rust via FFIs).
The Java Kernel in Delta 3.0 (the first release of the Java Kernel) released in October 2023 has already been adopted by Apache Druid to provide Delta Lake read support. In Delta 3.1, the Flink Sink includes an experimental Kernel integration that reduced the Flink pipeline initialization time by 45x (that is, by faster table metadata fetch) when writing to an 11 PB table with 7M files. With the upcoming Delta 3.2, Kernel will support time travel, For more information, see the following:
- Deep dive into the Kernel concept
- Talk at the Data + AI Summit 2023
- User guide and examples for Delta Kernel Java
- Good byte-sized issues for contributing to the Delta Kernel Java
While we are racing to add all the existing protocol features support to this ground-up reimplementation in Delta Kernel, the rest of the connectors continue to add major enhancements. A few highlights are as follows:
-
Apache Flink - Delta connector for Apache Flink saw major improvements
- Delta Sink is now production-ready with DoorDash using to ingest PBs of data / week into Delta tables.
- Read support, SQL support and Catalog support has been added to Flink.
-
Trino - The Delta Trino connector now supports Deletion Vectors, Column Mapping, and other key features from the main Delta Lake spec. It also saw performance improvements across the board.
-
Apache Druid - Apache Druid 29 has added support for Delta Lake using Delta Kernel.
-
Delta Rust (delta-rs crate / deltalake PyPI) - This immensely popular project (2M+ PyPI downloads/month as of April 3, 2024) has added many API improvements:
- Support for popular operations -
DELETE, UPDATE, MERGE, OPTIMIZE ZORDER, CONVERT TO DELTA - Support for table constraints - writes will ensure data constraints defined in the table will not be violated
- Support for schema evolution
With these improvements, you can do more advanced operations on Delta tables directly from your Rust and Python applications.
- Support for popular operations -
-
Support for Delta in GenAI tools - This deltalake now powers multiple new experimental integrations for Python libraries important in the current #GenAI world.
- Delta Torch for Pytorch (read the blog)
- Delta Ray for Ray
- Delta Dask for Dask
-
Delta Sharing - Delta Sharing has added support for securely sharing tables with Deletion Vectors via a new protocol, Delta Format Sharing. This new capability shares the Delta logs with recipients which enables them to query their tables, preferably using Delta Kernel. Using this approach makes the sharing protocol future-proof to any advances in the Delta protocol.
-
Delta DotNet - New connector written a .Net binding on Delta Rust.
-
Delta Go - Contributed by Rivian, this is a new connector written completely from scratch in Go.
Out-of-the-box Performance
Another focus area over the last year has been on out-of-the-box performance. As mentioned above, the merge-on-read approach with Deletion Vectors can produce some impressive performance improvements.
MERGE, UPDATE, and DELETE commands all now support Deletion Vectors, with some pretty impressive results when you enable it on your Delta table.
- DELETE: 2x speed up since Delta 2.4
- UPDATE: 10x speed up since Delta 3.0
- MERGE: 3.7X speed up since Delta 3.1
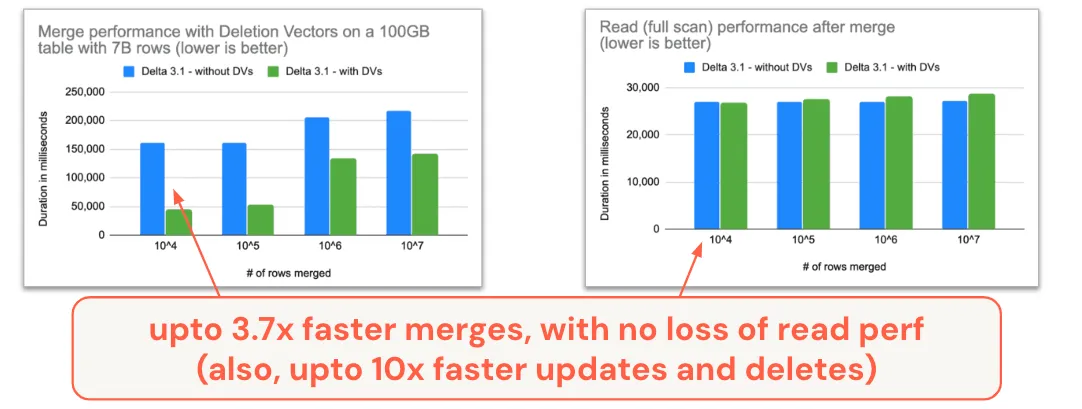
Note that the speed-up in merge does not hurt the read performance. Conventional wisdom and observations from other formats have until now suggested that the “merge-on-read” approach makes writes faster at the cost of slowing down reads, at least compared to copy-on-write. With our approach to merge-on-read, you don’t have to make hard performance trade-off choices; you can enable deletion vectors without any read performance regressions.
If for some reason, you choose to not enable deletion vectors, you can still enjoy 2x faster merges since Delta 3.0.
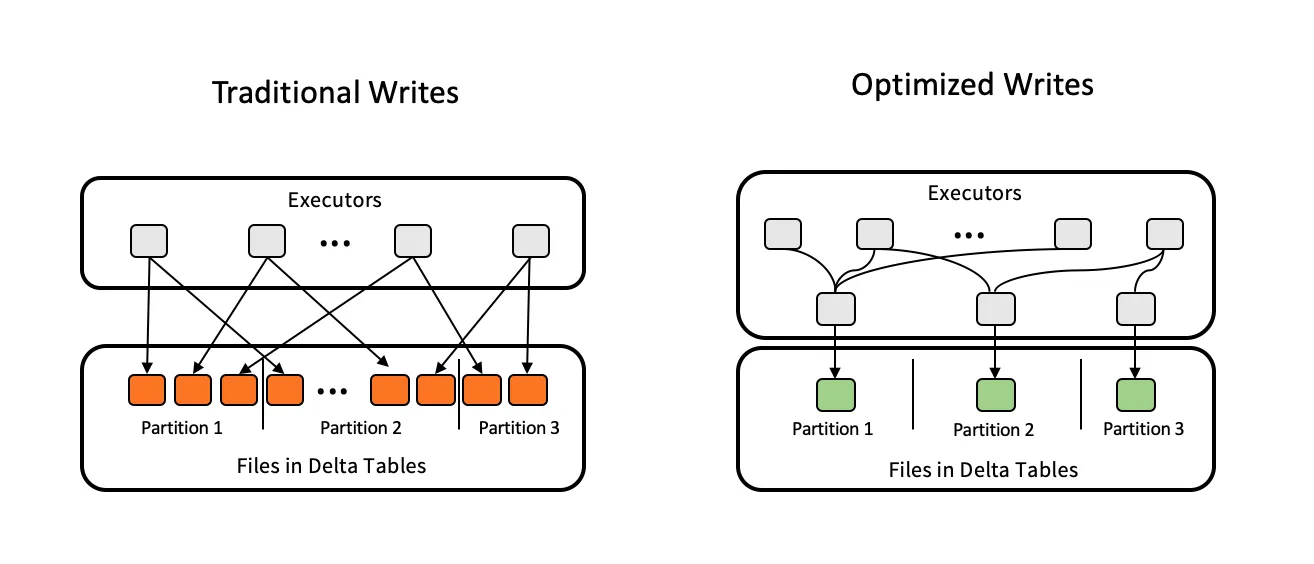
Out-of-the-box read performance has also gotten a boost over the last year, most recently with the addition of Optimized Write and Auto Compaction. Both of these features help solve the small file problem, in slightly different ways. Optimized Write forces any distributed Delta on Spark write operations to rebalance data using a data shuffle prior to writing files. This additional step adds a negligible amount of time to the write operation but significantly reduces the chances of writing small files and helps to preserve read performance. In cases of append-only streaming data ingestion, where each write includes only a small amount of data, Optimized Write can only do so much. This is where Auto Compaction provides additional performance protection. Auto Compaction performs a “mini Optimize” operation after each write to compact any small files left after previous writes. In combination, these two features improve out-of-the-box read performance.
Seemingly simple aggregation queries like MIN and MAX can be prohibitively time-intensive for large tables. These operations have been made faster by using the table metadata, reducing the need for full table scans and improving performance by up to 100x.
Looking ahead: Delta 4.0
The future of Delta Lake is marked by a commitment to pushing the boundaries of data technology while ensuring ease of use and access for our growing community. We plan to further enhance Delta Lake’s capabilities, particularly in areas like real-time analytics, machine learning integration, and cross-platform collaboration. We aim to make Delta Lake not just a storage format, but a comprehensive data management solution that addresses the evolving needs of modern data architectures. Expect to see deeper integrations with GenAI tools, more sophisticated data sharing mechanisms, and advancements in performance that redefine the benchmarks for data processing.
Specifically, a major event that we are excited about is Spark 4.0 that is expected to be released this year. This major release will bring new capabilities (e.g. Spark Connect) that will further empower the Delta ecosystem to innovate. If you are interested in a teaser, take a look at our recent community meetup where we discuss what to expect in Delta 4.0 on Spark 4.0. To stay tuned with the latest information in the Delta Lake project, please join our community through any of our forums, including GitHub, Slack, X, LinkedIn, YouTube, and Google Groups.
We’re excited to continue this path with our community, partners, and all data practitioners, driving towards a future where data is more accessible, actionable, and impactful than ever before!